





前往网站首页查看更多精彩内容👉https://imyshare.com/
可以结合AI一键让照片说话功能,快速生成微信动态背景图
也可以用MJ生成图片,然后用剪映生成动态图,这种方法相对麻烦些,不过也是不错的,此次分享的是另外一种方式
安装SadTalker
这款AI一键让照片说话的模型叫SadTalker,是由西安交通大学的研究人员提出的,它可以让照片里的人物跟随音频的输入动起来,且头部运动、面部表情比较真实
西安交通大学开源了人工智能SadTalker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片+音频就能生成高质量的视频。
论文:Learning Realistic 3D Motion Coefficients
通过人脸图像和一段语音音频生成说话的头部视频仍然包含许多挑战。即不自然的头部运动、扭曲的表情和身份修改。研究团队认为这些问题主要是因为从耦合的 2D 运动场中学习。另一方面,明确使用 3D 信息也存在表情僵硬和视频不连贯的问题。
为了学习真实的运动系数,研究人员显式地对音频和不同类型的运动系数之间的联系进行单独建模:通过蒸馏系数和3D渲染的脸部,从音频中学习准确的面部表情;通过条件VAE设计PoseVAE来合成不同风格的头部运动。
最后使用生成的三维运动系数被映射到人脸渲染的无监督三维关键点空间,并合成最终视频。音频可以是英文、中文、歌曲,视频里的人物还可以控制眨眼频率!
①建议先部署SD(stable-diffusion-webui)(星球里有很多教程)
因为SD已经支持了SadTalker的插件了,后续从SD生成的图片,都可以直接一键生成说话、唱歌视频。
(当然了,你也可以不部署SD,直接使用SadTalker)
②安装SadTalker插件:
打开并运行SD webui,然后选择“扩展”,在“从网址安装”里,输入以下地址:
https://github.com/OpenTalker/SadTalker
点击安装,需要等待3~5分钟

安装完成后,重启一下SD webui,即可在功能栏里看到“SadTalker”插件栏了
安装FFmpeg
FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序,是SadTalker运行的必要支持程序。
下载链接:https://www.gyan.dev/ffmpeg/builds/ffmpeg-git-full.7z
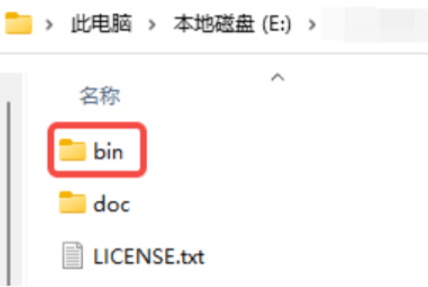
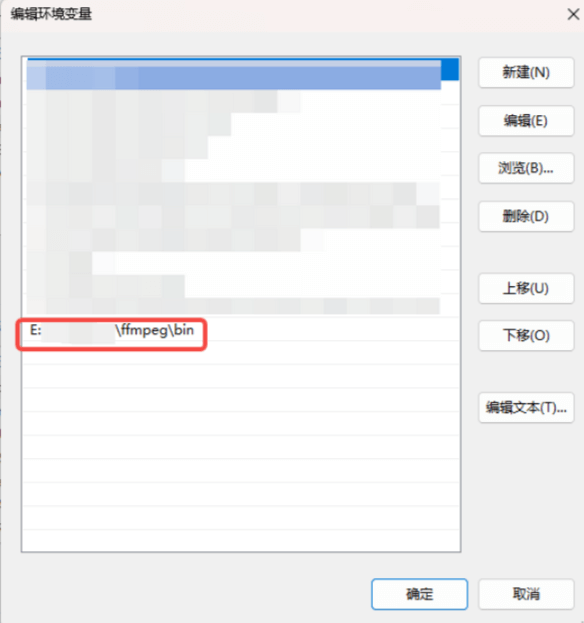
解压后,需要将FFmpeg的bin文件夹路径添加到系统环境变量里
手动添加环境变量:控制面板→系统→高级系统设置→环境变量→Path→编辑→添加
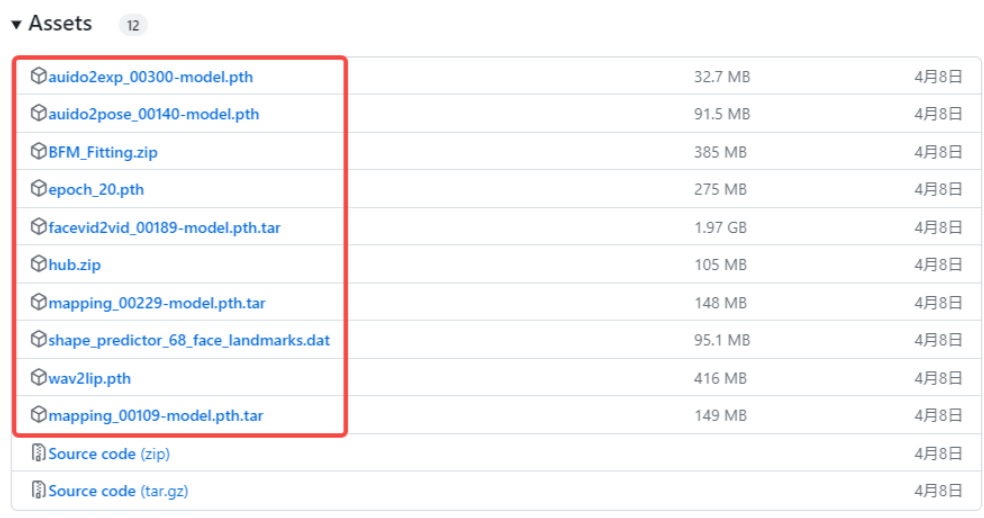
下载模型
运行SadTalker,还需要下载一些模型
下载链接:https://github.com/OpenTalker/SadTalker/releases
需要下载前面的10个文件
找到之前在SD里添加的SadTalker插件(在SD文件夹\extensions里),然后新建一个文件夹“checkpoints”

将上面下载的10个模型文件复制进去,其中BFM_Fitting和hub两个压缩文件还需要解压到checkpoints文件根目录中。
至此,你已经拥有了一键让图片说话的能力了
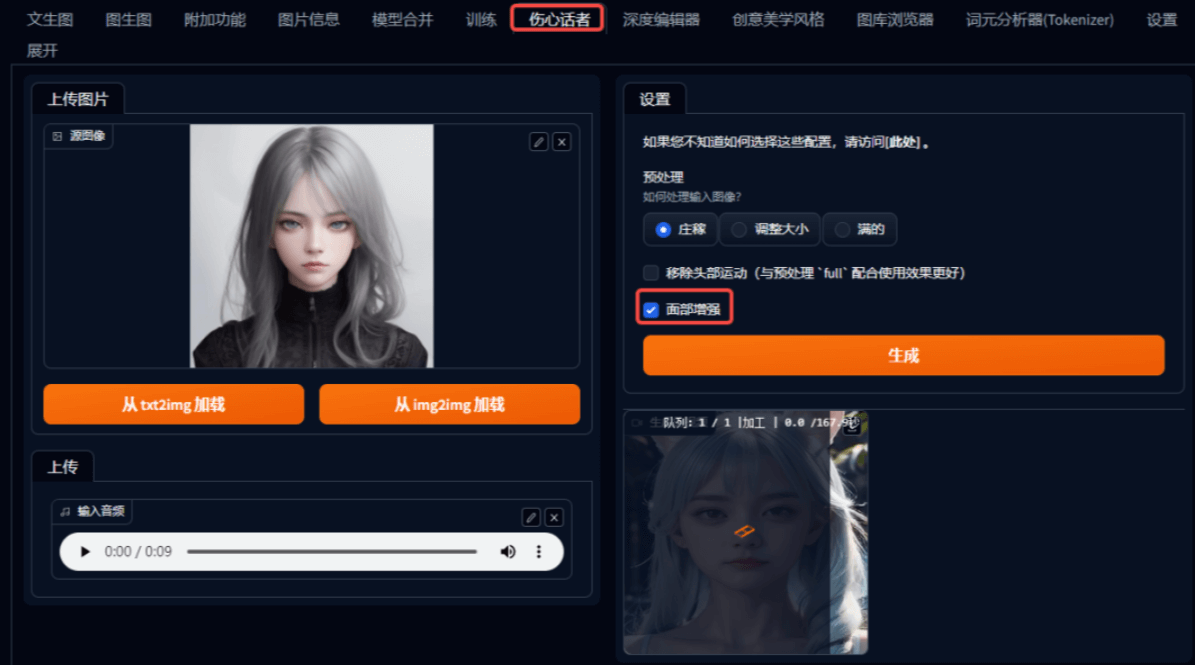
在SD webui的功能栏里,选择“SadTalker”,然后将图片(支持从SD中加载)和音频传入,音频建议在10秒以内,不然显卡压力有点大。点击“生成”按钮,即可一键使照片说话。
相关设置项说明:
- corp:图片被裁剪为方形(运算速度快,但如果传入的图片不是方形,最终视频会变形)
- resize:重新调整尺寸,可以使脖子和头部衔接自然,但代价是口型可能不太准
- full:完整体验(基本就是选它了)
同时记得勾选“面部增强”,使整体面部效果更加自然些
最终会说话、唱歌的小姐姐就出现在你的面前,她还会很自然地眨眼睛!
前往网站首页查看更多精彩内容👉https://imyshare.com/