





陆陆续续已经写过一些爬虫小项目了,考虑到后面可能不会持续搞爬虫了,借此做个小总结吧。本文主要从以下几个方面进行总结:
- 学会Python爬虫后,我们能做什么?——主要是看学会后对我们的工作、生活、兴趣等有没有什么帮助吧
- 什么是爬虫?——了解爬虫是在干什么,大致的过程是怎样的
- 举一个最基础的Python爬虫案例——对使用Python进行爬虫有更清晰的认识
- 入门Python爬虫需要学习的内容——了解入门Python爬虫的学习内容,以及大致的原理
- 爬虫进阶需要学习的内容——这一部分基本上算是爬虫最有意思,也是最有挑战的一部分了,而且不限编程语言,属于爬虫的核心
学会Python爬虫能做什么?
总结起来,其实爬虫最终就只有一个作用:将别人的数据为自己所用!至于用在哪里就有很多应用面了,大致也就以下四种了:
 数据搬运工
数据搬运工
本身不存储任何数据,只是把一些看不到的数据解析出来,做一个数据转发。比如我做的短视频无水印解析下载,就是通过抓包知道抖音、快手、tiktok等短视频软件官方是请求了哪个URL得到了无水印的视频链接,然后研究请求的时候带了哪些参数。大家只需要粘贴短视频的分享链接,然后我就就通过Python去模拟整个请求过程,把得到的无水印视频链接提供给大家下载。
当然还可以做其他的搬运啦,比如我做的利用Python实现百度网盘自动化:转存分享资源,获取文件列表,重命名,删除文件,创建分享链接等等,直接通过模拟请求将别人分享的百度网盘资源自动保存到自己的百度网盘,实现一些自动化的数据搬运!
数据永久存储
这个就比较容易理解了,就是把别人的数据存到自己的硬盘里面呗。是不是瞬间想到了小姐姐,哈哈哈~比如我做的利用Python爬取epubw整站27502本高质量电子书,并自动保存至百度网盘(内附分享),就是爬取epubw这个网站分享的所有电子书网盘链接,然后利用Python模拟百度网盘保存分享链接至自己的网盘的过程,最终将这27502本书籍存到自己的网盘。
这些爬下来的数据都存到自己的硬盘了,至于想干点啥,还不是自己说了算,哈哈哈~比如这位作者做的将知乎&豆瓣上的相亲贴爬下来,展示出来给广大单身的小伙伴提供便利。我们不生产对象,我们是对象的搬运工,哈哈哈~点击进入爱知乎(备注:有时候为了回避检查,仅限手机才能访问)
数据分析
这个就比较好理解了,就是爬取一些数据下来,做一些简单的数据分析和监控呗。比如这位程序员去买房,顺手就做了一个成都房源分析,程序员做事情就是这么实在,哈哈哈~
为大数据、机器学习等提供数据
这方面我目前只是知道可以这么干,但是具体的机器学习是怎么操作的,还是了解的甚少,需要持续学习😭。在此就膜拜一下大佬的作品:王斌给您对对联!
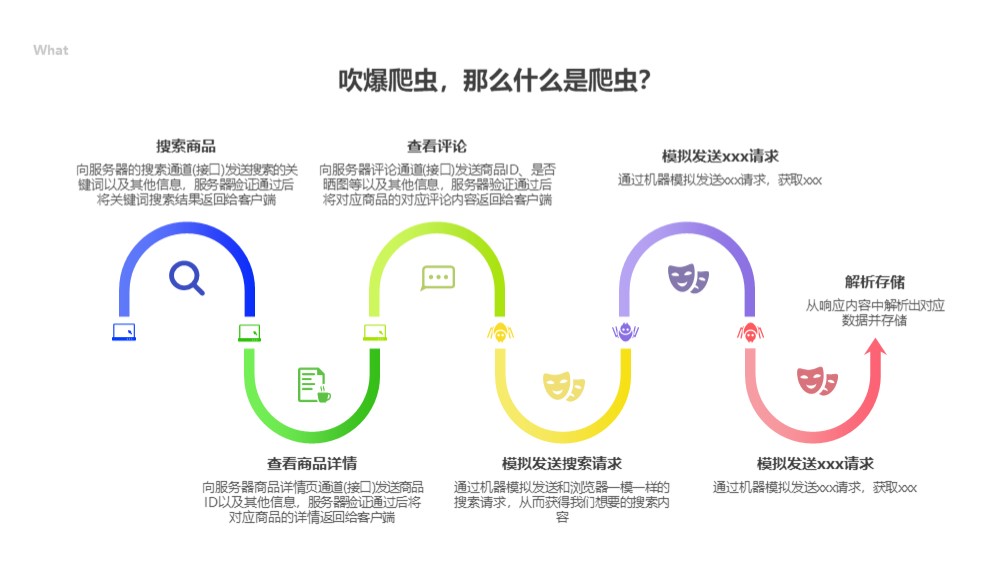
什么是爬虫?
技术的角度解释,爬虫其实就是使用代码模拟发送请求,并获取响应数据,然后解析响应数据,获取想要的那部分数据,最终存储解析出来的数据的一个过程。
通俗的来讲,怎么理解呢?比如现实中我们想要获取一个商品的评论,需要怎么操作呢?我们需要搜索到这个商品,点击查看商品详情,然后点击评论,就可以看到一条条的评论了。这个过程中就涉及到你的手机和淘宝之间进行数据交互了,那搜索的时候,淘宝怎么知道要给你商品了呢?而且怎么知道要给你什么商品数据的呢?这就依赖你的手机得告诉淘宝,我要搜索商品了,我搜索的关键词是xxx,淘宝收到你的通知后,说哦我知道了,我先找一找我存储的和xxx相关的商品,找到了发送给你。这个过程就叫请求和响应了,你请求淘宝,淘宝响应你。我们爬虫做的事情就是通过代码去自动模拟这个请求,获取响应,最终得到响应中的数据的过程。
 一个简单的Python爬虫案例
一个简单的Python爬虫案例
 一个简单的Python爬虫案例
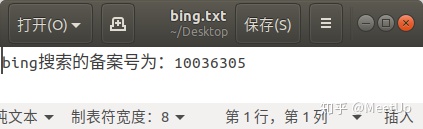
一个简单的Python爬虫案例比如我们想写一个爬虫程序,自动为我们获取bing搜索首页的备案号。
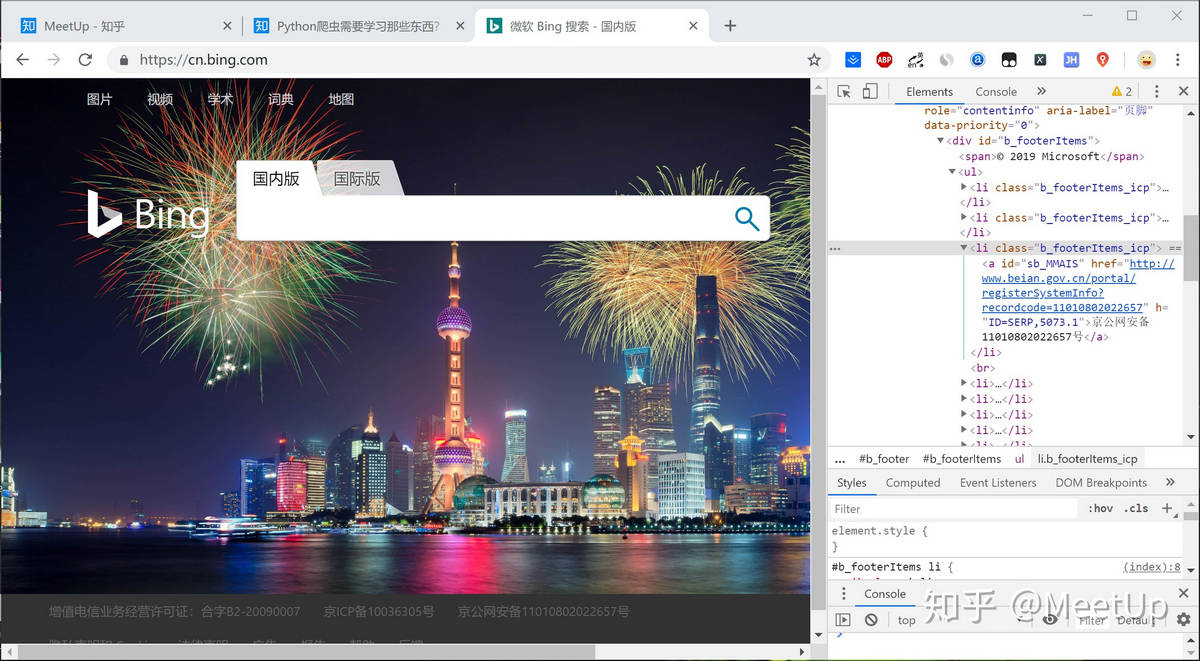
1.首先我们就要找到能获取bing首页的URL,这里不用找,就是:https://cn.bing.com/。然后我们就向这个URL发送一个get请求,并得到响应内容。
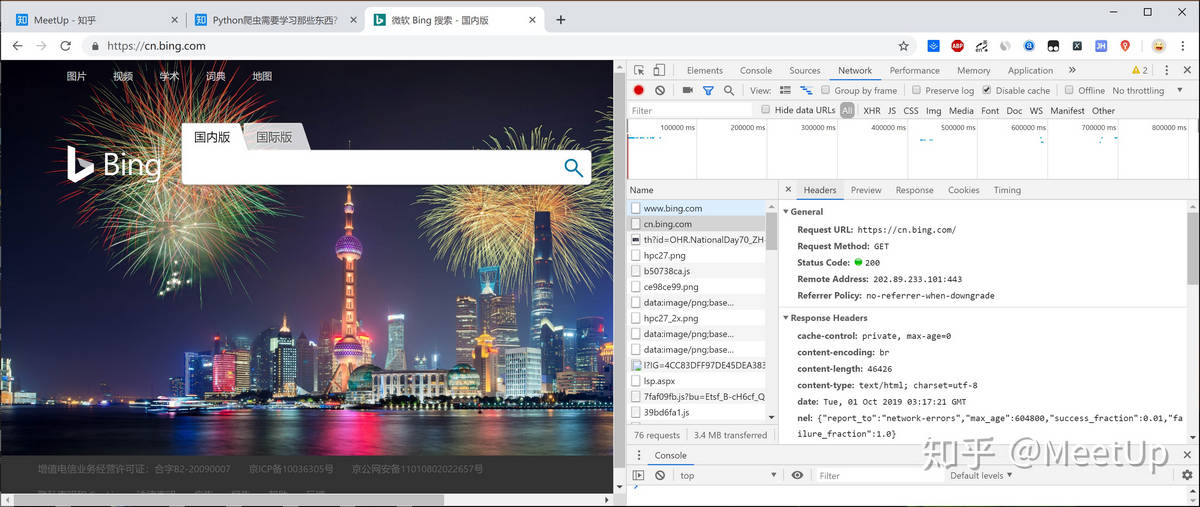
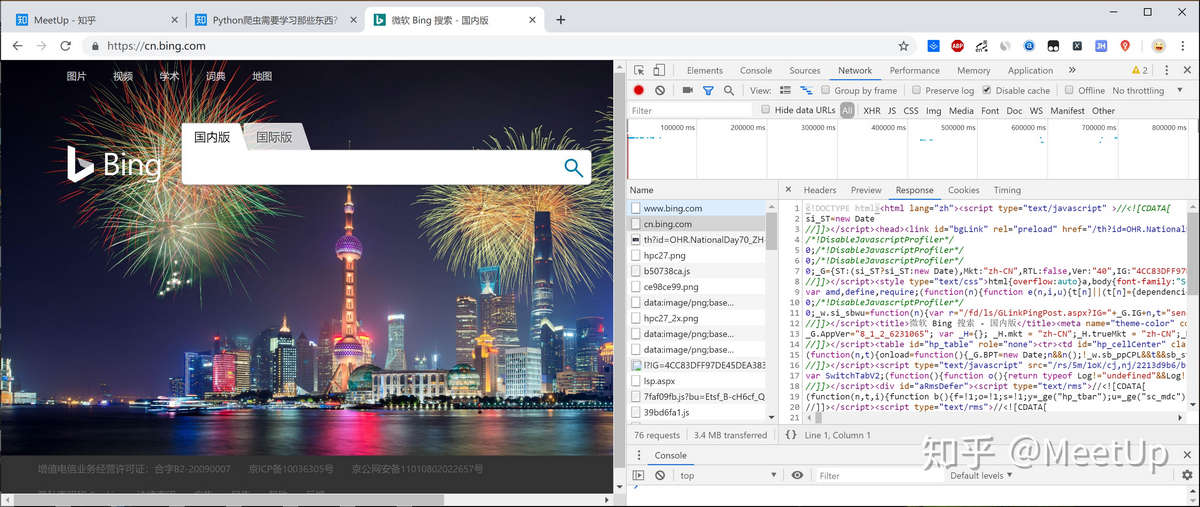
2.然后用正则规则去匹配响应中介于“京ICP备”和“号”中间的内容;
3.最终将解析出来的备案号,存储至一个叫bing.txt的文件中;
对应的完整代码如下:
# coding="utf-8"
# 导入requests库,用于实现HTTP请求
import requests
# 导入正则库
import re
# 请求bing搜索首页,并获取响应
response = requests.get("https://cn.bing.com/")
# 响应头部内容
print(response.headers)
#响应体内容
print(response.text)
# 解析响应内容,获取其中我们想要的备案号
number = re.findall(r'京ICP备(.+?)号', response.text)[0]
print(number)
# 将备案号存储到txt文件中
f = open("bing.txt", 'a')
f.write("bing搜索的备案号为:%s" % number)
f.close()
程序运行后最终输入的结果如下(对比一下,是不是和浏览器获取到的内容一致),以及我们是否获取到了需要的备案号,并且保存了下来:
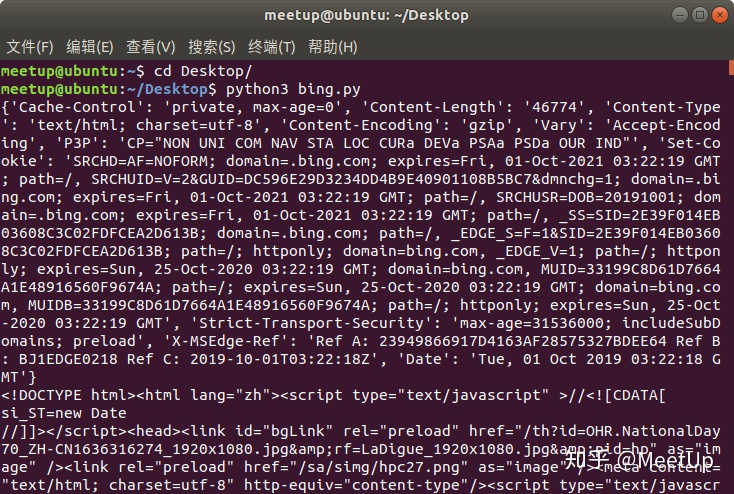
入门Python爬虫需要学习的内容
基于上面一个简单的案例,基本可以确定想要学会爬虫基础,我们需要掌握以下知识点:
- 抓包:主要是获取可以通过哪个URL能获取到我们需要的数据,也就是常说的抓包获取接口;
- 学习HTTP原理:主要是了解请求和响应中各个字段的含义即可;
- 手动模拟构造请求:写代码前使用软件模拟请求,看我们是否准确的研究除了获取想要数据的完整过程;
- 写代码实现模拟请求:掌握基础的python代码,核心常用的也就几句;
- 学会常用的几种解析数据的方式:主要是为了把我们想要的数据从一大堆数据中分离出来;
- 学会常用的几种数据存储方式:解决爬取后的数据存储问题;
- 掌握懒人爬虫方法:比如通过代码控制浏览器,实现浏览器自动化获取数据,完全不用研究什么请求响应;
抓包
通过抓包知道从哪个URL才能获取到你想要的数据,请求此URL需要哪些参数。如果只是网站中的数据,我们只需要打开浏览器的开发者工具(Chrome浏览器快捷键:F12),并且切换至Network一栏即可查看所有的请求和响应了。比如点击“翻译”按钮,获取有道翻译是调用的哪个URL获取的翻译结果。
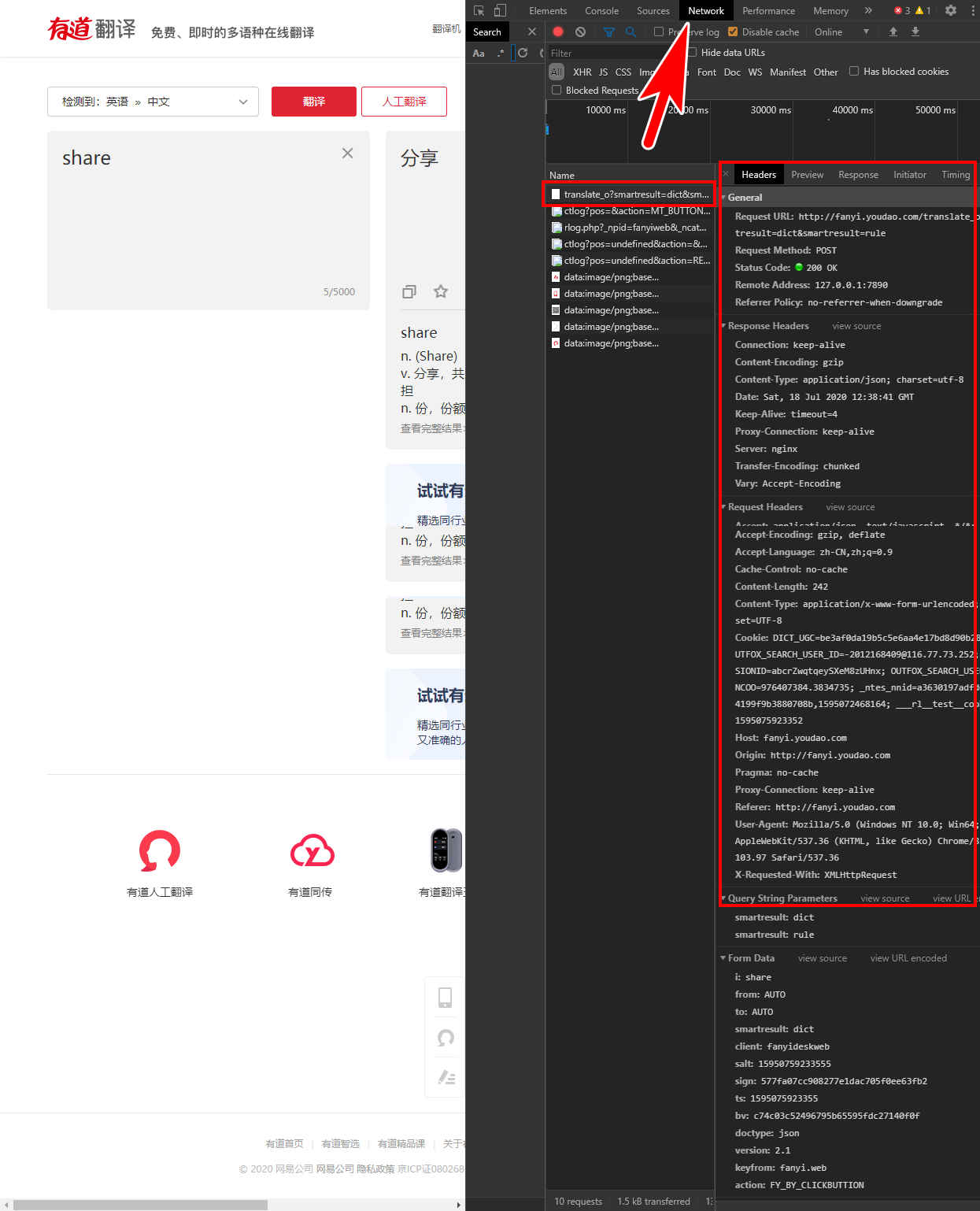
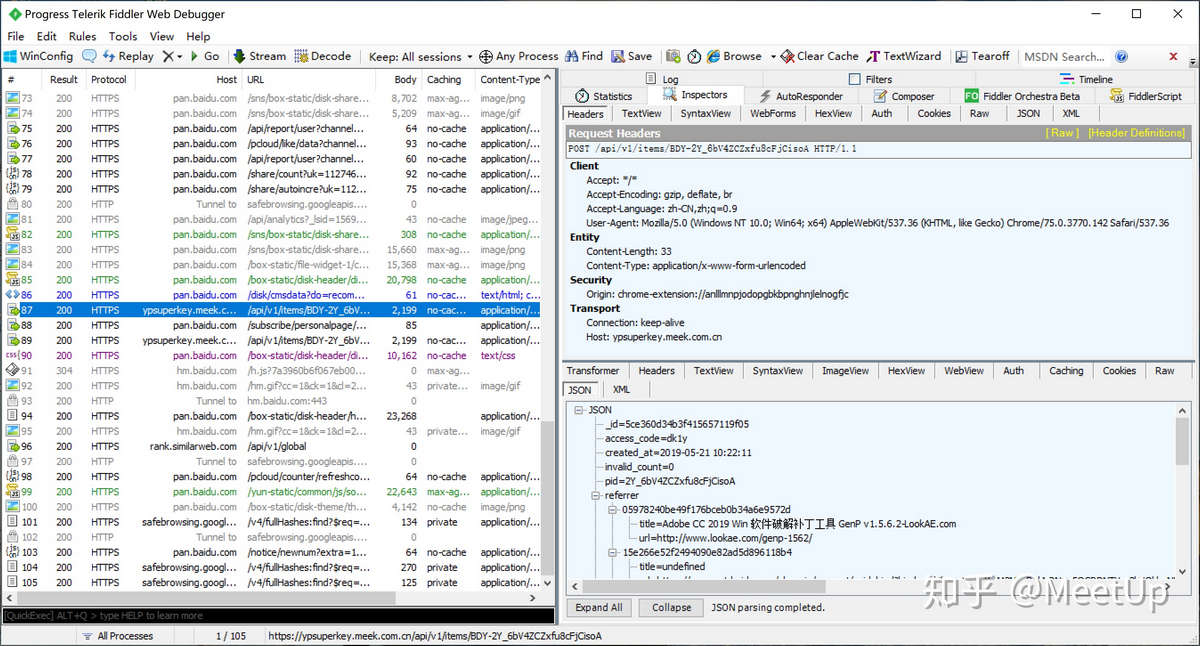
如果想要获取App的数据呢?那就只能借助抓包工具了,常用的抓包工具有Fiddler、Wireshark等,新手推荐用Fiddler,手机上还可以使用Stream等App直接在手机上进行抓包。使用也非常简单,只需要打开抓包软件,然后在需要抓包的app中正常操作一遍需要获取数据的过程,然后切换回抓包软件,就可以看到刚刚操作过程中的所有请求和响应了!
学习HTTP原理
我们抓包获取到对应的接口后,想要看懂请求和响应中的东西,还得学习简单的HTTP原理,其实只需要掌握请求和响应中常用的各个字段的含义,基础部分掌握ser-agent、host、origin、cookie、表单参数等就够用了。这部分百科中就有很详细的解释,就不做详细介绍了。

手动模拟构造请求
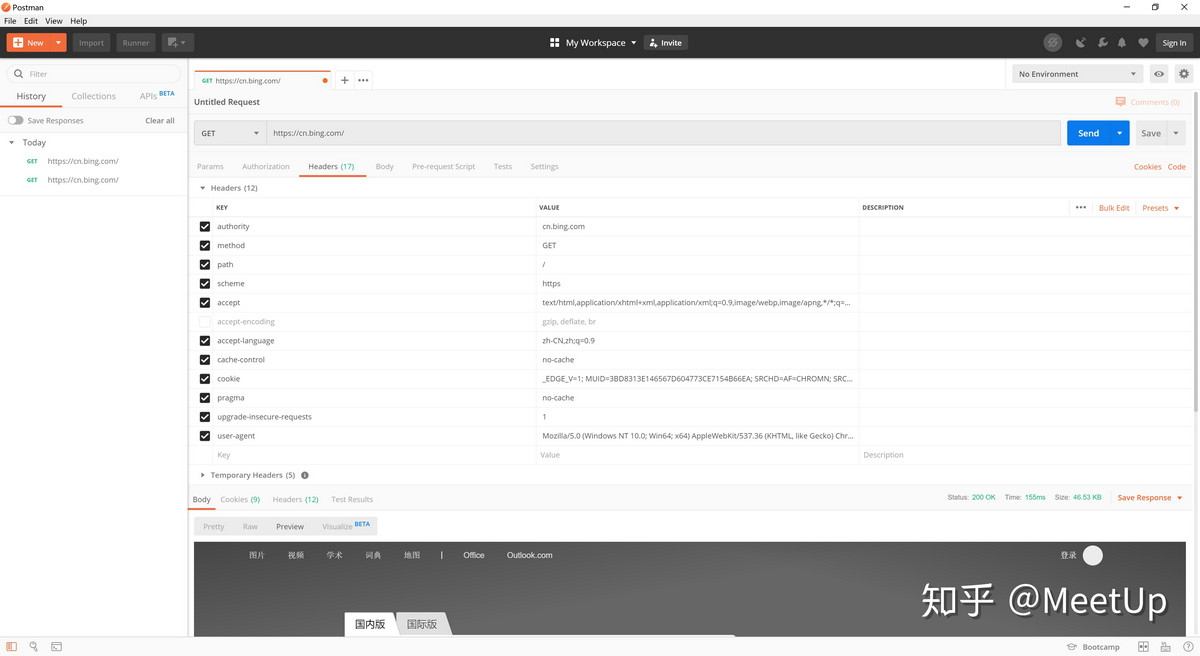
我们知道了通过请求哪个接口可以获取到我们想要的数据,也知道了请求的时候需要携带什么参数了,是不是就可以立马写代码实现了呢?写代码是比较耗时的一个过程,所以写之前我们最好验证一下我们研究的是不是正确的,验证通过后再写代码,避免重复工作。推荐使用Postman进行模拟验证,使用起来也是非常简单,只需要输入我们研究好的各项参数,然后点击“发送”即可验证是否有效了。
写代码实现模拟请求
上面的一切理论知识具备后,就可以开始写python代码实现爬虫了。对于基础的爬虫,模拟请求核心代码就一行!这大概就是“人生苦短,我要学Python”的原因把!
import requests
# 通过get请求获取响应
response = requests.get(url, headers, params)
# 通过post请求获取响应
response = requests.post(url, headers, data)
学会常用的几种解析数据的方式
拿到response响应后,我们如何准确的从响应中提取出我们需要的数据呢?这就需要掌握几种常用的文本解析方法:正则匹配、Beautifulsoup、Xpath、json解析。其中正则匹配性能最好,但是研究正则规则比较麻烦,Beautifulsoup语法人性化,最简单,但是性能差一些,所以我一般选这种的xpath解析。
推荐安装浏览器插件Xpath Helper,可以直接在浏览器中先模拟xpath解析。常用的xpath语法也不多,百度一下一大堆,比如:Xpath高级用法,不用刻意记忆,用几次就熟练了。
其他几种解析也都有模拟工具可以模拟啦,这样可以保证写代码的高效性!比如在线正则匹配测试,还可以一键生成正则匹配的代码,各个语言都兼容!比如JSON-handle插件可以解析json格式的数据等。
学会常用的几种数据存储方式
我们拿到数据后,难免有需要存起来的时候,就又要学习各种存储😭。对于文件类的数据还比较好说,直接将二进制数据存储到文件即可。但是实际上我们大多数情况下还是爬取的关联性的结构性数据,比如一个用户的用户名、头像、邮箱等等。这时候就要用到数据库了,所以还得学习:MySQL、Sqlite3、Mongodb、Redis,有时候还得学习存储到excel或者直接存储json文件等。
不过好在“人生苦短,我要学Python!”,上面提到的都是有对应的库可以直接使用的,比如数据库操作,推荐直接使用ORM的方式进行操作,这样就省去了深入学习数据库,学习SQL语句了。然后查看数据时使用可视化的软件(比如:Navicat Premium)连接数据库查看数据即可~
这里大概介绍一下ORM操作数据库,可以使用sqlalchemy这个库,这个库可以将数据库中的字段和我们代码中的类和属性进行映射对应,然后我们就可以通过操作类和属性的方式进行操作数据库了,具体看下面这个例子应该就能明白:
# coding='utf-8'
from sqlalchemy import Column, Integer, String, VARCHAR, DateTime, Numeric, create_engine, ForeignKey
# from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.exc import IntegrityError
# from sqlalchemy.sql.expression import func
import os, datetime
import warnings
import time
# 忽略sqlalchemy警告
warnings.filterwarnings("ignore")
# 创建对象的基类:
BaseModel = declarative_base()
# 定义代理对象:
class Proxy(BaseModel):
# 表的名字:
__tablename__ = 'proxies_proxy'
# 表的结构:
id = Column(Integer, primary_key=True, autoincrement=True)
ip = Column(VARCHAR(16), unique=True, nullable=False)
port = Column(VARCHAR(10), nullable=False)
type = Column(VARCHAR(5), nullable=False)
hidden = Column(VARCHAR(2), nullable=False)
speed = Column(Numeric(5, 2), nullable=False)
country = Column(VARCHAR(2), nullable=False)
area = Column(VARCHAR(100))
origin = Column(VARCHAR(20), nullable=False)
create_time = Column(DateTime(), default=datetime.datetime.utcnow)
update_time = Column(DateTime(), default=datetime.datetime.utcnow, onupdate=datetime.datetime.utcnow)
class DbOperate(object):
def __init__(self):
# 初始化数据库连接:
# self.engine = create_engine('sqlite:////home/meetup/Desktop/db.sqlite3', echo=False, connect_args={'check_same_thread': False})
self.engine = create_engine('mysql+pymysql://local:连接密码@账户:端口/数据库名', echo=False)
# 创建DBSession类型:
self.DBSession = sessionmaker(bind=self.engine)
self.session = self.DBSession()
# print('数据库操作初始化完成')
def create_table(self):
# 创建BaseModel所有子类与数据库的对应关系
# print('开始创建表')
BaseModel.metadata.create_all(self.engine)
# print('创建表完成')
def drop_db(self):
BaseModel.metadata.drop_all(self.engine)
# country: 国内:1,国外:2; type: HTTP:1,HTTPS:2; hidden: 透明:1,匿名:2,高匿:3;
def get(self, country='', type='', hidden=''):
try:
if(country == '' and type == '' and hidden == ''):
return self.session.query(Proxy.id, Proxy.ip, Proxy.port, Proxy.type).all()
else:
return self.session.query(Proxy).filter(Proxy.country==country, Proxy.type==type, Proxy.hidden==hidden).order_by(Proxy.speed).all()
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '从数据库获取IP失败: ', Exception, ':', e)
self.session.close()
def update(self, id, speed):
try:
proxy = self.session.query(Proxy).get(int(id))
proxy.speed = speed
self.session.commit()
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '更新数据库中的IP失败: ', Exception, ':', e)
self.session.close()
def delete(self, id):
try:
proxy = self.session.query(Proxy).get(int(id))
self.session.delete(proxy)
self.session.commit()
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '删除数据库中的IP失败: ', Exception, ':', e)
self.session.close()
def add(self, proxy):
try:
self.session.add(Proxy(ip=proxy['ip'], port=proxy['port'], type=proxy['type'], hidden=proxy['hidden'], speed=proxy['speed'], country=proxy['country'], area=proxy['area'], origin=proxy['origin']))
self.session.commit()
except IntegrityError:
self.session.close()
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'IP保存至数据库失败: ', Exception, ':', e)
self.session.close()
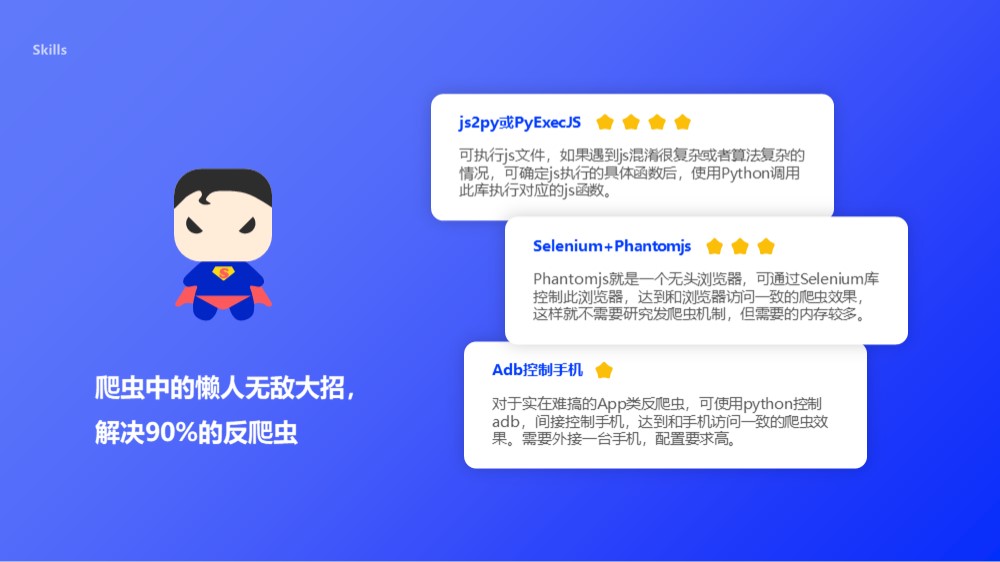
懒人爬虫方法
刚开始学的时候去研究请求、响应这些,有时候会感觉很枯燥,而且难免会遇到稍微难一点爬虫。这时候就直接使用自动化神器吧🤦,为此掉一堆头发不值得,毕竟后面慢慢学会了,这些都不是问题了!常用的有3中:
- Selenium+Phantomjs:Phantomjs就是一个无头浏览器,可通过Selenium库控制此浏览器,达到和浏览器访问一致的爬虫效果,这样就不需要研究发爬虫机制,但需要的内存较多;
- Adb控制手机:对于实在难搞的App类反爬虫,可使用python控制adb,间接控制手机,达到和手机访问一致的爬虫效果。需要外接一台手机,配置要求高;
- js2py或PyExecJS(属于进阶内容了):可执行js文件,如果遇到js混淆很复杂或者算法复杂的情况,可确定js执行的具体函数后,使用Python调用此库执行对应的js函数;
- 可视化爬虫工具:这属于额外介绍的内容了,如果代码都不愿写,就可以使用可视化爬虫工具了,只需要点击几下进行设置,然后点击运行即可开始自动爬虫了。是不是想不到还有这等工具,哈哈哈~推荐:八爪鱼等等
爬虫进阶需要学习的内容
了解了上面整个过程后,基本写一下基础的爬虫就没问题了。但是实际项目中往往还会遇到各种各样的问题,比如卧槽他这个请求中的参数哪里来的?怎么生成的?卧槽我的IP怎么突然爬不了了?为啥有验证码?为啥返回的内容里面混杂着各种垃圾数据?为什么我爬到的数据和我看到的数据不一样?为啥爬虫速度这么慢?爬虫中断了怎么继续?等等。遇到这些类似的问题不要慌,说明进步的时候到了,哈哈哈~😂具体进阶还需要有以下内容需要深入学习:
- 攻克反爬虫:和对方程序员较量,通过各种手段绕过或者模拟对方的反爬虫验证;
- 提升爬虫的稳定性和效率:我们要保证爬虫长久运行不出错,断点了可以继续爬虫,不遗漏数据,加快爬虫等;
什么是反爬虫?
其实很简单理解,有爬虫就会有反爬虫,毕竟对方程序员也不想你轻轻松松就把他的数据搞走了,会通过各种障碍阻止你爬取数据!对于没写过爬虫的新人来说,可能感受不深刻,看个简单的视频应该就能感受到了~
常见的反爬虫
1.请求上的反爬虫
常见的就是会在请求中加一些算法相关的参数,然后做前后端校验,然后前端生成这个参数的代码进行混淆加密,让爬虫者不知道参数是怎么生成的,简直是程序员为难程序员啊!不过好在有一门技术叫逆向研究~目前我也是只掌握了基础的js逆向研究,可以解决网页端的加密参数,想入门的看下面的视频即可。对于app端和桌面端的软件层面的逆向研究,目前还不会😭不过没关系,看后面的常用的反爬虫思路一样可以解决大部分反爬虫,哈哈~
2.机器验证(甚至机器学习风控)
常见的会做登录验证、人机验证(比如:验证码,拖动验证等等)、访问频率检测、访问环境等综合维度评测等。
登录验证比较好说,我们只需要在请求的时候带上登录相关的cookie或者token参数即可。而且可以注册多个账号,维护一个cookie或者token池,每次请求的时候取不同的用户信息,达到扰乱对手的目的。
人机验证,如果是比较出名的人机验证,GitHub上都有开源的方法,直接下载使用即可,不用费脑筋了🤦。如果是比较基础的验证码,我们也可以尝试动手解决,比如我之前做了一个简单的验证码识别:利用Python进行简单的OCR图像识别,解决爬虫中的验证码、图像文字识别等问题
访问频率限制,一般会基于用户去限制,或者基于IP去限制。如果是基于用户限制,维护一个用户池即可,每次随机取一个用户。如果是IP限制,就需要有一个IP代理池了,每次请求的时候加上高匿名的代理IP,这样就可以隐藏自己的真实IP了。可以花钱买,或者自己维护一个,比如我自己维护的免费代理池:利用Python打造免费、高可用、高匿名的IP代理池
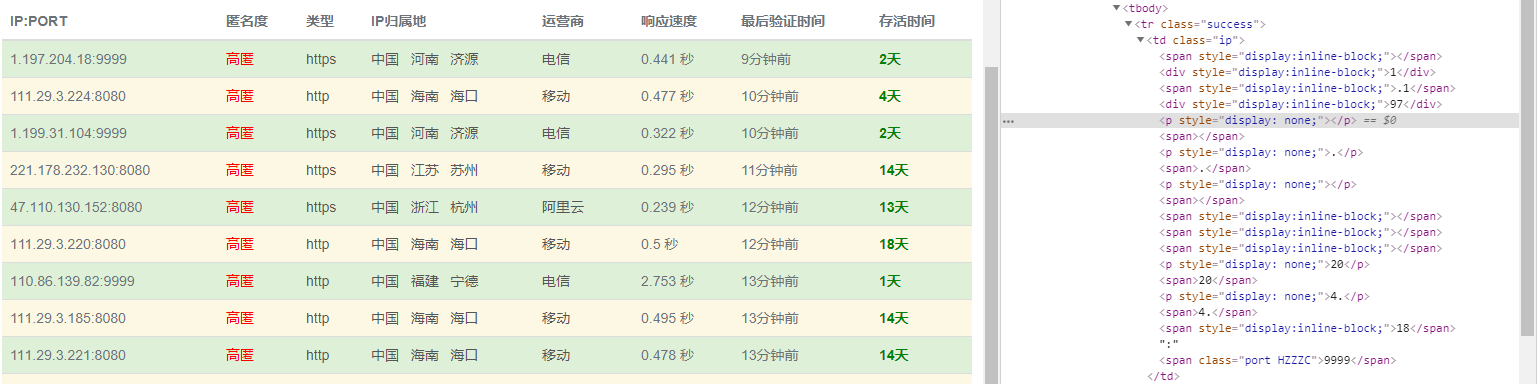
3.内容上的反爬虫
常见的有两种,一种是文本混淆(如下图),在文本中混入各种标签,标签里面混杂各种无效内容,然后利用隐藏属性将这些内容隐藏,达到爬虫可见,用户看不到的目的!
还有一种就是将文字内容转化为图片,图片转化为文本等等手段,这个就又要使用到OCR识别了,就不多介绍了!
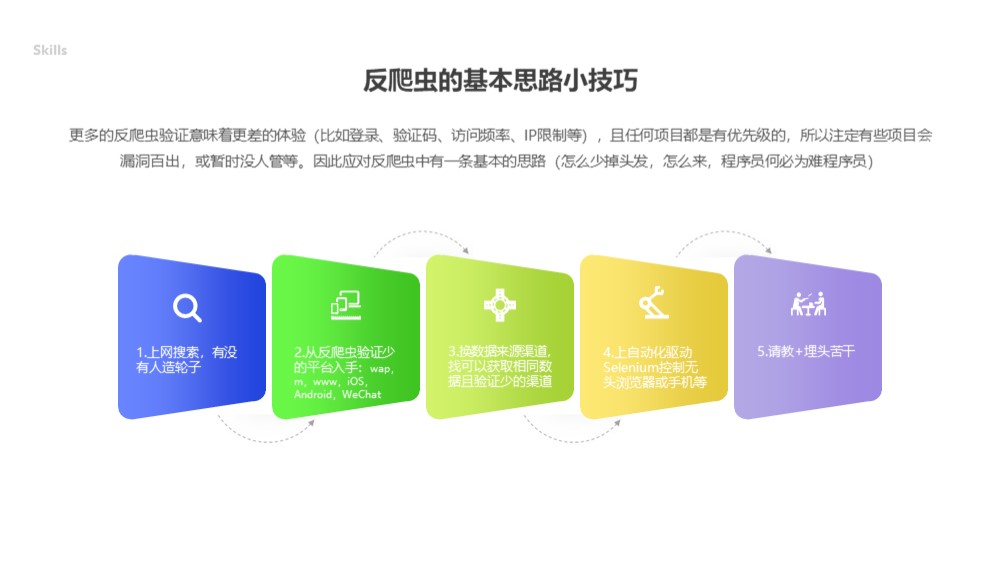
常用的反爬虫思路
看到上面的反爬虫手段后,估计已经瑟瑟发抖了,这得学习多少东西啊(可怜的头发😭)!不过还是有巧可取的啦~下面介绍一下常用的反爬虫思路,让我们少掉一点头发😂。总结起来实际上就一条路子:对于这些反爬虫得先想办法绕过,实在不能绕过再请教大佬,请教大佬没用再自己硬着头皮研究,哈哈哈~
不要觉得这些方法不好使,如果觉得不好使,可能是还没掌握精髓,哈哈哈~比如我就用巧办法解决了抖音的无水印视频解析,tiktok的无水印视频解析,具体参见:巧办法解析tiktok无水印视频下载地址,轻松搞定tiktok无水视频下载!
提升爬虫的稳定性和效率
这部分就比较逻辑性了,没那么多玄学~干就完了
稳定性靠的是代码的健壮性(该加异常捕获的都加上🤦),还有就是断点继续后的去重了,掌握数据库去重(查数据是否存在)、缓存去重(利用Redis中的set类型)、内存去重(HashSet、Bit-Map等等)中的一种就够用了,后面两种都有内存风险,所以大批量数据推荐数据库去重,小批量可以使用Set集合等。
效率,有两条路可以解决,如果是同一台机器上跑爬虫,可以做多进程+多线程(或者协程)操作,或者直接使用成熟的爬虫框架Scrapy。还有一条路就是分布式爬虫,比如将不同的事情放在不同的服务器上执行,然后有一台服务器负责统一调度。
相关资源推荐: