





直接下载无水印的抖音短视频
如果看此片文章的目的仅仅是下载无水印的抖音短视频,就用不用往下看了,直接点击这里进行解析下载:抖音短视频无水印解析下载。如果你是来学习爬虫思路,爬虫奇淫巧计的,就可以继续往下看了,看完才是精华~
抖音火了之后,一直还是短视频行业的老大。视频质量自然相对其他平台也好很多,上面各种有才华的网红,各种有意思的视频,也怪不得走到哪都能看到抖音的身影。我偶尔下班累的时候也会刷一刷,遇到有意思的视频会保存到本地。但是发现直接通过App保存后,视频是带有水印的,很影响后续观看!一怒之下想研究怎么保存无水印的抖音短视频。
然而实际上直接百度抖音无水印解析,就已经有很多结果了。有很多都是在线解析的网站,把分享链接粘贴进去,点击解析,就可以获取无水印的短视频链接了,通过这个链接就可以直接保存抖音无水印短视频至本地了。一个个做的还挺好用的,所以如果你只是想方便地下载抖音无水印短视频,可直接用百度中的在线网站即可。
如果你和我一样喜欢瞎研究,那就跟我一起看看吧。本篇文章主要以抖音无水印短视频解析下载为实例,介绍爬虫中的变向思维:遇到难啃的骨头,没必要硬碰硬,换个角度,说不定更简单!(大家都是程序员,何必为难同行[捂脸])当然如果你走的是软件逆向路线,就当我没说,直接去参考四哥抖音解混淆逆向分析的文章吧:
抖音Android版app逆向
抖音火山Android版app混淆
文中涉及的代码(Python版)及接口,不保证是最新的,但是万变不离其中,思路还是没问题的。不过我有时间的时候也会更新最新的代码,欢迎持续关注!
1.抖音基础无水印解析版本
虽然平时喜欢研究,但是有时候也挺懒的[捂脸]。第一步,遇到问题直接上GitHub搜了一下(遇到问题先上网搜一下,Google什么的都可以的),结果就发现了可用版本。此版本算是一个巧办法吧,不过对于我们平时写代码来说,快速完成业务才是王道啊,虽然这样有点不负责任,哈哈哈。原理是直接请求抖音短视频分享链接,获取html内容。
<script>
$(function(){
require('web:component/reflow_video/index').create({
hasData: 1,
videoWidth: 720,
videoHeight: 1280,
playAddr: "https://aweme.snssdk.com/aweme/v1/playwm/?s_vid=93f1b41336a8b7a442dbf1c29c6bbc569e748f551cc25ae99221c35b080756a55a1dd75742144fa8e4c080d418b69e554150d60e91f33d2a629aeb3b8ba82eb4&line=0",
cover: "https://p9.pstatp.com/large/275c1000436aced6f739d.jpg"
});
});
</script>
然后提取HTML内容中的playAddr链接,然后将链接中的“playwm”改为“play”,“&line=0”改为“&line=1”。然后再请求更改后的链接,请求的时候获取302跳转链,此链接就是抖音无水印的链接。链接是有时效性的,一段时间后会失效。对应的Python版本核心代码如下(此部分代码已失效):
res = requests.get(url=self.share_link, headers=self.headers)
video_link = re.findall(r"playAddr: \"(.+?)\"", res.text)[0]
real_link = re.sub(r"playwm", "play", video_link)
real_link = re.sub(r"&line=0", "&line=1", real_link)
# 此处要用手机浏览器UA
res = requests.get(real_link, headers=self.headers1, allow_redirects=False)
real_link = res.headers['Location']
2.通过Fiddler抓包获取官方接口(Android)
通过搜索来的方法,用了一段时间后就被封了。第二步,只能自己动手了,啥也不说,咋先抓个包看看再说(按照官方流程,全程抓包)。玩过抖音的朋友,都知道抖音短视频可以以链接的形式进行分享。我们不妨将分享后的链接直接在手机浏览器中打开,看看抖音官方是如何获取无水印视频的。此过程全程使用Fiddler进行抓包,分析官方的请求路径。用浏览器打开后,进行播放,发现播放的直接是带水印的视频。不过点击顶部的“打开看看”选项,直接就打开了抖音app(这里我使用的Android测试机),并播放此视频。到此就算抓包结束了。
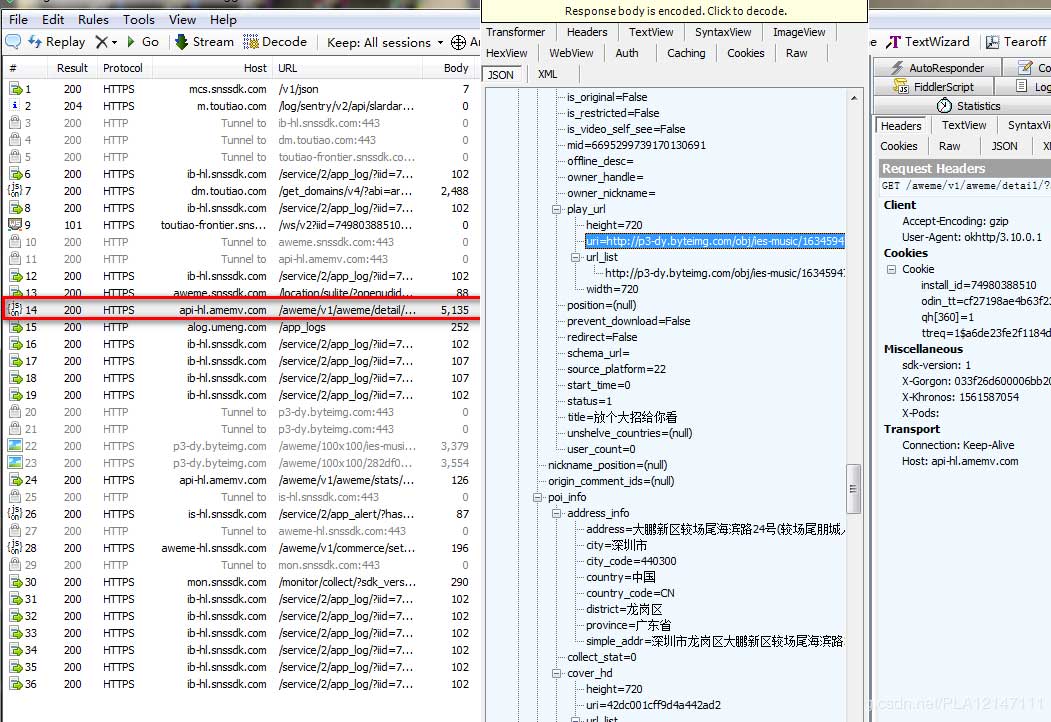
然后我们一条一条的去看刚刚的抓包数据,看看有没有获取可疑数据的接口。基本上也就是先简单的过一遍Response,看看有没有和此视频相关的数据就可以了。结果就发现了有个Response基本包含了此视频的所有信息,比如视频标题、封面、无水印链接等等。所以基本可以确定这就是我们想要的接口了,然后去看一下请求头,意外发现基本没什么验证,而且还是json格式的,岂不是美滋滋,哈哈~
此接口只需要一个动态参数,那就是短视频的aweme_id。这个参数很容易获取,直接请求分享链接,然后获取302跳转链接,链接里面就包含这个id了,这里就不做详细介绍了。下面是此接口的抖音无水印短视频解析爬虫Python版核心源代码(此接口现在已失效,而且业余Coding,代码比较糙,将就看哈[捂脸]):
class Douyin(object):
def __init__(self, share_link, proxies, ua='Mozilla/5.0 (iPhone; CPU iPhone OS 8_0_2 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12A405 Safari/600.1.4'):
self.headers1 = {
'User-Agent': ua,
'Host': 'v.douyin.com',
}
self.headers2 = {
'User-Agent': 'okhttp/3.10.0.1',
'Accept-Encoding': 'utf-8',
'Host': 'api-hl.aweme.com',
'sdk-version': '1',
}
self.share_link = share_link
self.proxies = proxies
def getData(self):
res1 = requests.get(self.share_link, headers=self.headers1, allow_redirects=False)
aweme_id = re.findall(r"video\/(.+?)\/", res1.headers['Location'])[0]
api_link = 'https://aweme-hl.snssdk.com/aweme/v1/aweme/detail/?origin_type=web&retry_type=no_retry&device_id=67913728029&ac=wifi&channel=baidu&aid=1128&app_name=aweme&version_code=660&version_name=6.6.0&device_platform=android&ssmix=a&device_type=HUAWEI+VOG-L29&device_brand=HUAWEI&language=zh&os_api=19&os_version=9.0.0&uuid=867000796904268&openudid=502b73dc52682085&manifest_version_code=660&resolution=640*960&dpi=320&update_version_code=6602&_rticket=1561064545285&mcc_mnc=46007&js_sdk_version=&ts=1561064545aweme_id=' + aweme_id
res2 = requests.get(api_link, headers=self.headers2)
json_res = json.loads(res2.text)
real_link = json_res['aweme_detail']['video']['play_addr']['url_list'][0]
# return {'real_link':real_link, 'sort':sort}
3.通过其他接口爬取数据
发现上面那个接口后,以为自己可以用一段时间,可以高枕无忧了。结果有一天午休的时候,没忍住,看到一个有意思的抖音视频,想保存,发现自己的脚本无效了。哎呀,抖音的接口改的这么频繁,看来抖音的程序员工作不饱和啊,哈哈哈~抱着我不管,我就要保存抖音无水印视频的心态,当时就决定抓个包看一下。
由于本人不是程序员,所以公司电脑上基本没装编程相关的工具。上班期间有想法了,基本都在手机上操作一下,所以手机上装了JSBox、Pythonista、Stream、Thor、Anubis一类的App。这次就使用Stream在iPhone上抓包(基本上一键的,没什么难度,这里也不做介绍)。还是按照上次的思路,全程抓包一遍,然后看请求响应,最终也找到了我们想要的接口了。但是发现这接口验证的参数很多,而且还得研究这些参数怎么生成的,我像是会去研究这些的人吗?哈哈哈~
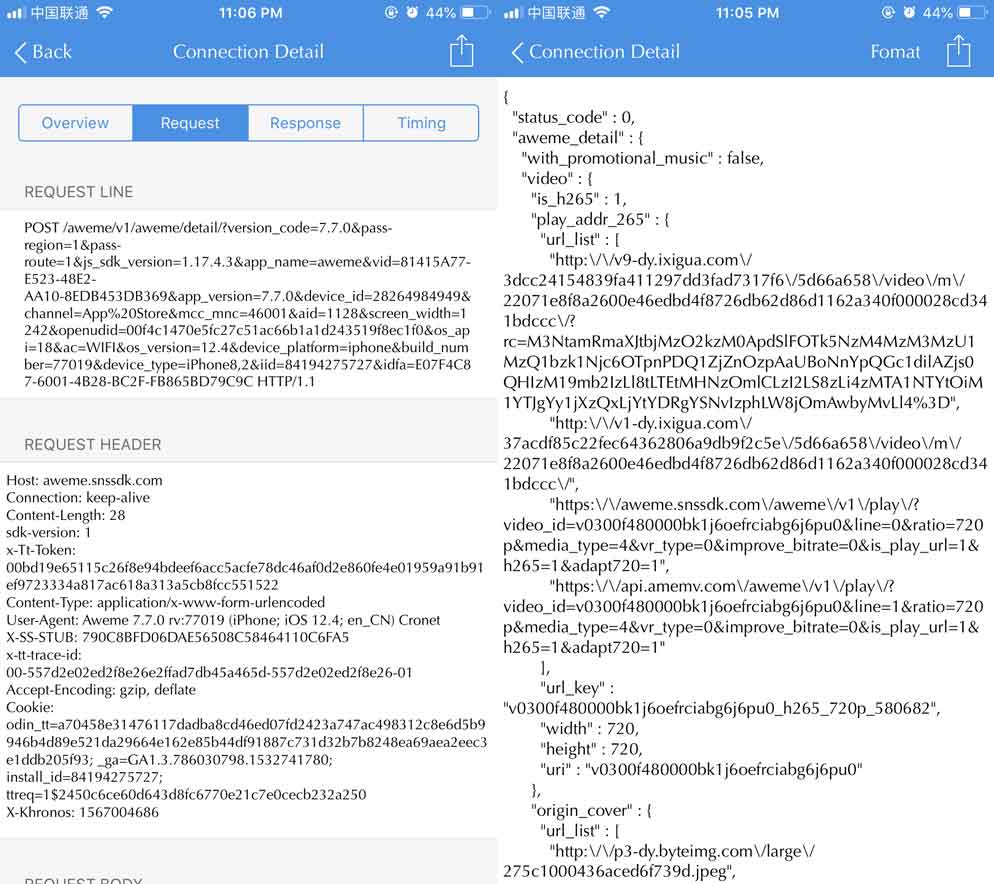
所以果断跳过,看看有没有其他方式。第三步,换个渠道获取数据(直接请求,间接请求)。早有耳闻,字节跳动很有野心啊,想在头条上撬动百度搜索,所以在头条上打通各种数据,什么新闻啊,视频啊,小视频啊等等。说到这里,大家应该知道我要干什么了:通过头条的接口获取抖音的数据!
打开头条就发现有个小视频入口,切换后,里面就是各种短视频了。但是没有定位到我想要的短视频的突破口,就在打算换新思路的时候,意识到顶部的搜索入口。试着搜了一下视频的描述,结果真搜到了,而且播放的时候是无水印的。
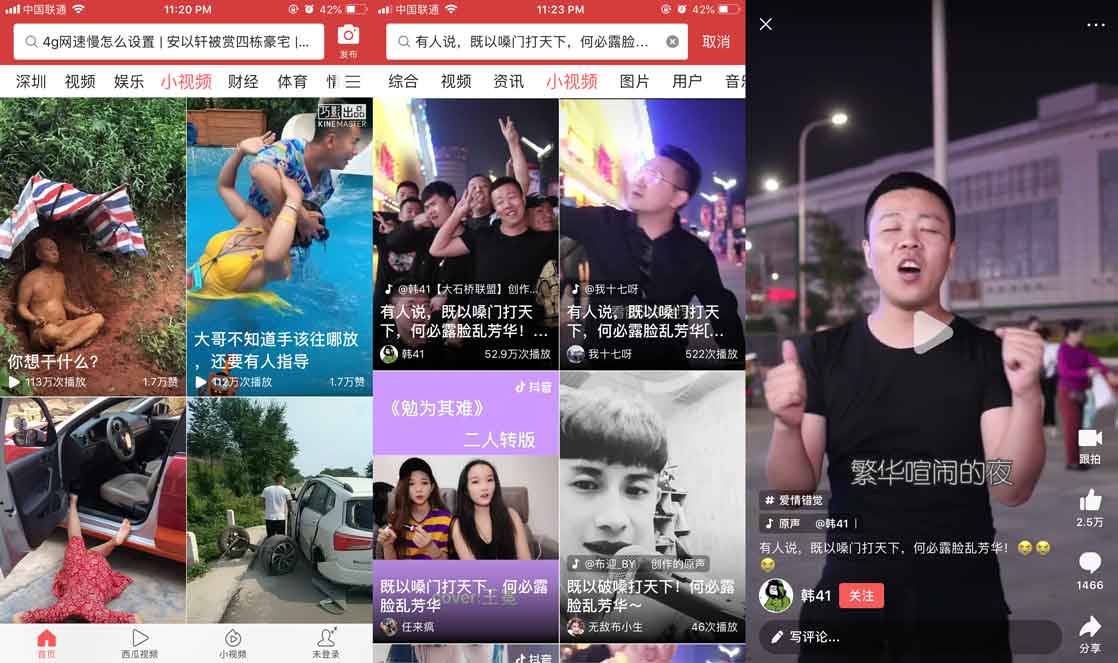
所以赶紧使用Stream抓包看看,因为请求很少,很快就找到了我们想要的请求接口。但是看到这请求头,传的参数太多了。哎哟,掉头发!都懒得验证了,直接打算换平台。
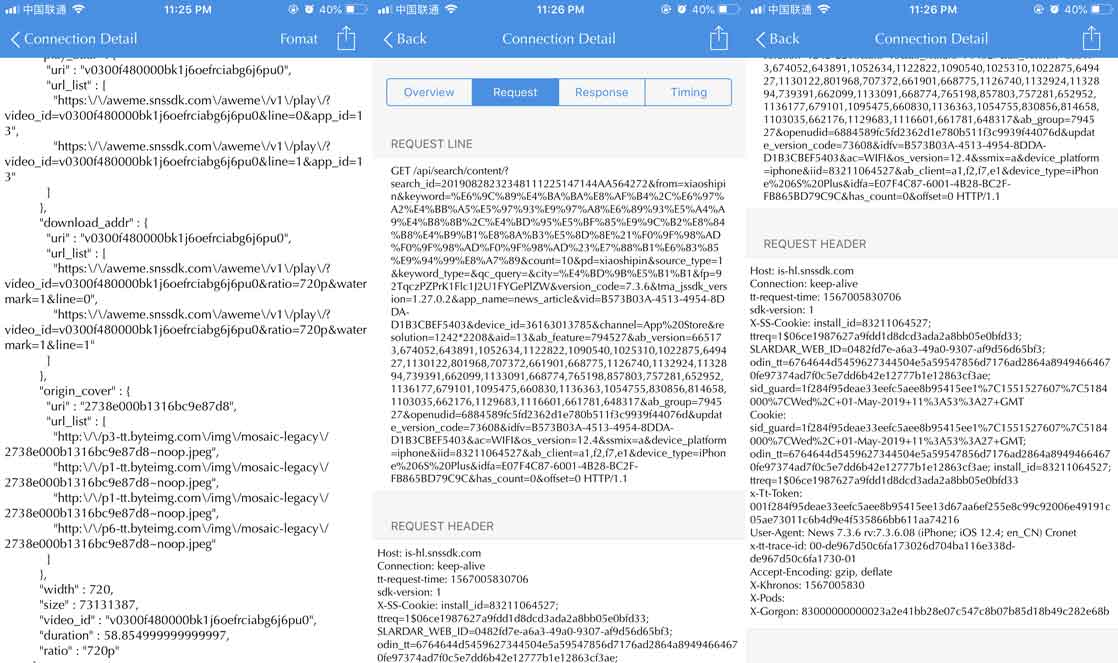
第四步,换个平台获取数据(Android App、iOS App、手机web端、PC端等等)。头条这种平台都是有web端的,所以直接去web上抓包再看看。这时候不得不打开电脑看看了,毕竟手机抓包还是不方便。但是又不想在公司电脑上装抓包工具,所以直接浏览器F12打开开发者工具将就看一下吧。还是按照手机上的思路,打开头条网页版(在浏览器的开发者选项中点击手机图标,即可模拟手机请求),然后搜索短视频的描述,然后切换只小视频tab,得到我们需要的搜索结果。而且意外发现此搜索接口,没有什么参数验证,美滋滋~
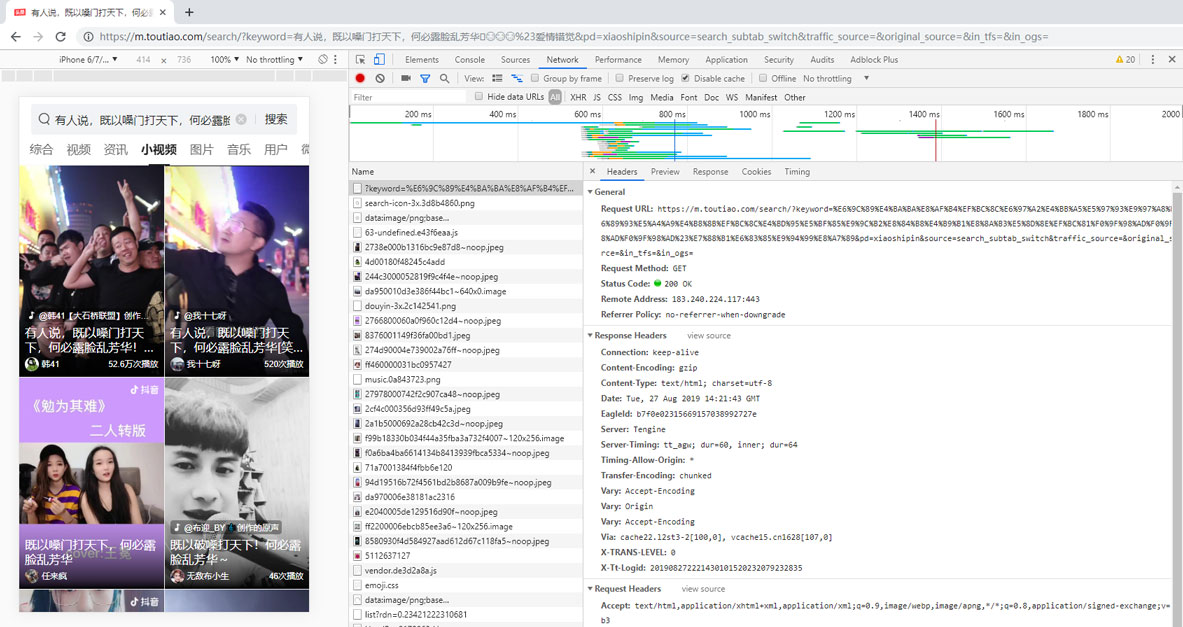
然后直接用开发者选项中的选择工具,选择我们搜索到的短视频,查看对应的html内容。又是意外发现视频链接就在这个a标签中藏着呢。
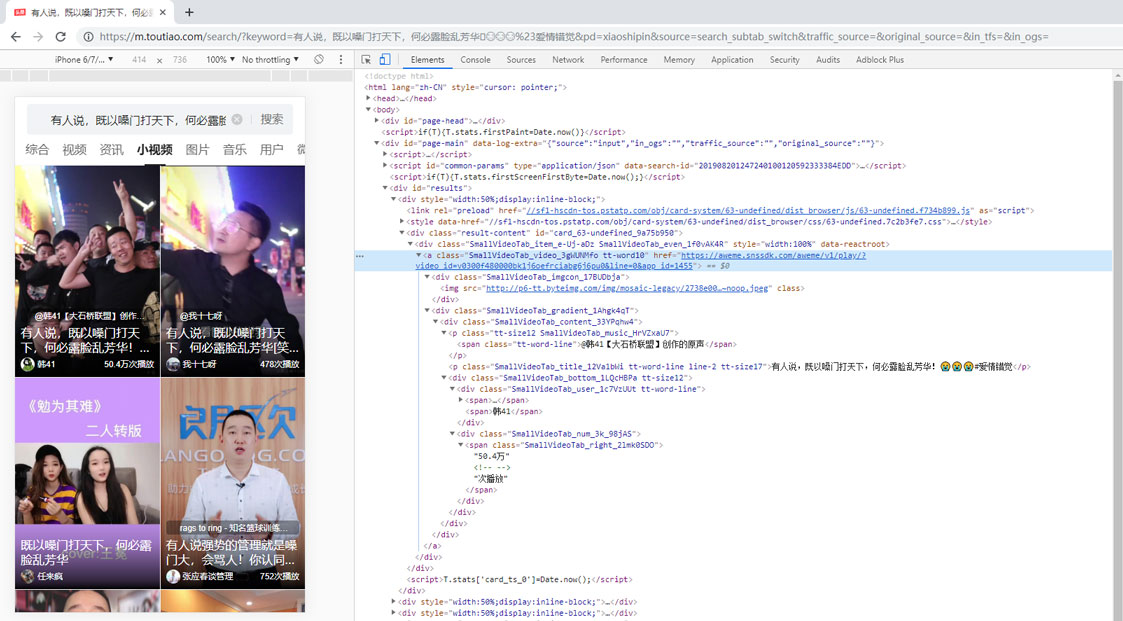
然后,我们就手动访问一下这个链接呗,看看是不是我们想要的抖音无水印短视频。还是用模拟手机请求,发现果然是无水印的!而且视频的无水印真实链接就藏在302跳转中,直接取302跳转的Location就可以了。
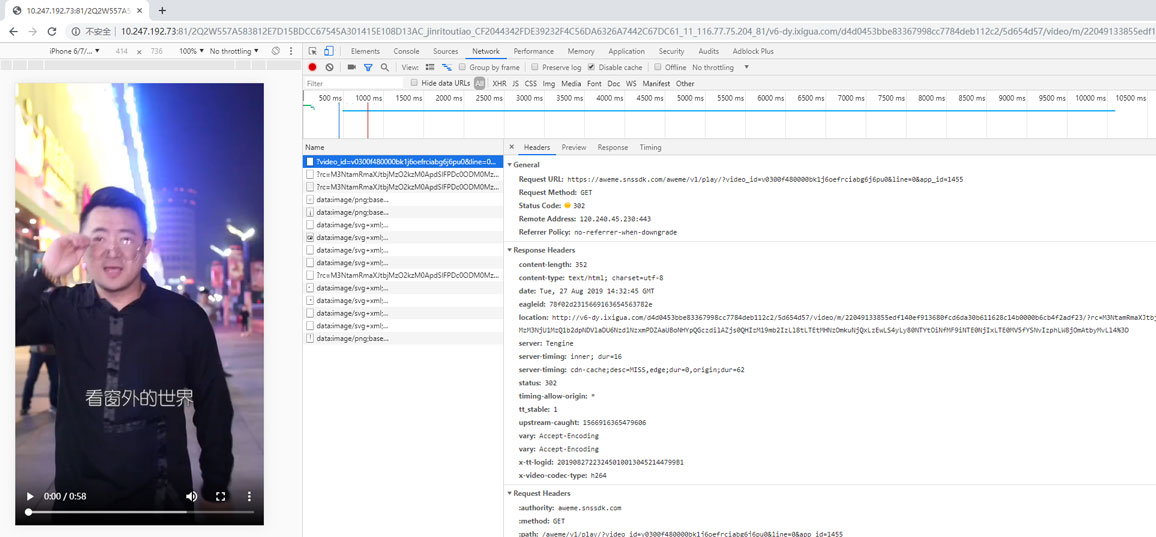
然后,下班回家我就根据中午在公司抓包的几个接口,写好了这个简单的脚本。原理就是先请求抖音短视频的分享链接,获取视频描述和作者,然后用头条的手机网页版小视频搜索接口搜索视频描述,然后遍历搜索结果,描述相同的就是我们需要的视频,然后获取此视频的a标签的链接,请求此链接并获取302跳转的Location,就得到了无水印的视频链接了。对应的Python版核心代码如下:
# 方案6
res2 = requests.get(location, headers=self.headers2)
author = re.findall(r'<p class="name nowrap">(.+?)<\/p>', res2.text)[0][1:]
des = re.findall(r'<p class="desc">(.+?)<\/p>', res2.text)[0]
api = 'https://m.toutiao.com/search/?pd=xiaoshipin&source=search_subtab_switch&traffic_source=&original_source=%20HTTP/1.1&in_tfs=&in_ogs=%20HTTP/1.1&keyword='
url = api + urllib.parse.quote(des)
try:
random_proxy = random.choice(self.proxies)
build_proxy = {'http': random_proxy.ip + ':' + random_proxy.port, 'https': random_proxy.ip + ':' + random_proxy.port}
res3 = requests.get(url, headers=self.headers3, proxies=build_proxy, timeout=3)
except:
res3 = False
else:
sort = 'proxy'
if(not res3):
res3 = requests.get(url, headers=self.headers3)
sort = 'real'
selector = etree.HTML(res3.text)
items = selector.xpath('//a[@class="SmallVideoTab_video_3gWUNMfo tt-word10"]')
link = ''
for item in items:
try:
des_temp = item.xpath('.//p[@class="SmallVideoTab_title_12Va1bWi tt-word-line line-2 tt-size17"]/text()')[0]
author_temp = item.xpath('.//div[@class="SmallVideoTab_user_1c7VzUUt tt-word-line"]/span/text()')[0]
except:
pass
# print(difflib.SequenceMatcher(None, des_temp, des).quick_ratio())
# print(difflib.SequenceMatcher(None, author_temp, author).quick_ratio())
else:
if(des_temp == des):
link = item.xpath('@href')[0]
if(not link):
return {'status':False, 'des':'为能解析出无水印视频!'}
else:
res4 = requests.get(link, headers=self.headers4, allow_redirects=False)
return {'status':True, 'real_link':res4.headers['Location'], 'sort':sort}
4.总结
换个角度让爬虫更简单,总结一下换个角度基本思路大概就是下面这些了:
- 先在网上搜一下,有没有现成的方法或者接口可用,毕竟爱造轮子的程序员还是很多的[笑哭];
- 网上没有现成的,自己先按照官方数据获取流程,全程抓包,看看情况再做决定;
- 如果接口验证参数多,且复杂,考虑换个平台。比如App反爬虫力度大,不妨试试iOS端→Android端→网页端→微信端,看哪个平台反爬虫力度小,就从哪个平台下手;
- 换平台难度还是很大的时候,考虑换数据来源渠道,看看有没有其他相似数据的地方。比如获取用户数据,可以从用户主页获取,也可以从数据详情页获取,还可以从搜索渠道获取;
- 全分析了一遍,如果还是不好绕过反爬机制,管他三七二十一,网页端直接上Web Driver。比如Selenium+PhantomJS或者Selenium+Chrome Driver;
- 到了这一步了,不妨上网请教一下大佬,大佬随便指点两句,你可能就明白怎么骚操作了[笑哭];
- 最后实在没辙了的话,就只能硬着头皮去逆向分析它的各种验证算法呗。不过还是建议先网页端,最后才考虑App逆向;
备注:
我按照上面的思路至少找到了抖音无水印解析的四五个可用接口,但是涉及到抖音的利益,这里就不公开太多了。大家按照这个思路,总会发现些什么的。不过要是大家都非常有兴趣的话,可以关注公众号:iMyShare,然后后台留言给我,需要的人多的话,我会写个接口给大家用哈~(非商用!)
最后说一句大实话,只要你够骚,头发就掉的少,哈哈哈哈~
相关资源推荐:
- Python爬虫快速入门,爬虫进阶学习路线,以及爬虫知识体系总结
- 利用Python爬取epubw整站27502本高质量电子书,并自动保存至百度网盘(内附分享)
- 利用Python实现百度网盘自动化:转存分享资源,获取文件列表,重命名,删除文件,创建分享链接等等
- 抖音短视频无水印解析下载,换个角度让爬虫更简单
- 巧办法解析tiktok无水印视频下载地址,轻松搞定tiktok无水视频下载!
- Python利用youtube-dl库快速搭建视频解析下载网站,支持下载1000+网站的视频
- 利用Python打造免费、高可用、高匿名的IP代理池
- 利用Python进行简单的OCR图像识别,解决爬虫中的验证码、图像文字识别等问题