





玩过爬虫的小伙伴应该都会遇到一种情况,由于访问频率过高(多进程、多线程一时爽),或者模拟请求时,某些参数传递不对等等情况,被对方程序检测到是爬虫程序在访问,然后被对方封了IP,禁止访问。这时候,人性一点的后端,会在一段时间后,为你解封IP。意识到这个问题后,遇到不是特别急用的数据时,我们可以检查一下请求参数,是否有遗漏,确定无误后,去掉多线程,并为请求添加sleep来降低请求频率,然后就又可以继续愉快的爬了。但是事实上在爬虫与反爬虫的斗争中,往往爬虫都是很暴力的(程序员就喜欢为难程序员,哈哈哈),往往都不甘心IP被封,而这时候就需要我们使用匿名代理来爬虫。
代理IP的原理及爬虫中的使用
代理IP的原理就和我们平时使用的小梯子差不多哈,就是我们发送请求的时候经过代理,让代理去请求,代理请求完成后,再将请求结果返回给我们。而且代理IP有透明、匿名、高匿的区别,透明代理情况下,对方还是能够知道我们的真实IP的;匿名的情况下,对方知道我们使用了代理,但是无法确定我们的真实IP;高匿情况下,对方基本就啥都不知道了。
代理在爬虫中的具体使用,相信应该不陌生了,大多数的库都是加一个proxies参数即可,这里以requests为例:
response = requests.get(url, proxies={'http': '117.69.12.222:9999', 'https': '117.69.12.222:9999',} headers=headers,)
何为IP代理池?
当我们有了匿名或者高匿的代理来伪装我们的真实IP,就又可以继续我们高效率的爬虫了。然而在大规模的爬虫中,我们使用一两个代理也是不够用的。因为代理IP也是固定的,访问太频繁的话,也会被对方封掉的。所以我们就需要大量的匿名或者高匿代理IP,这时候IP代理池的概念就诞生了,意思就是一个装有很多IP的容器,我们需要用的时候,可以随时从里面随机取一个。很多个代理IP一起干,既可以达到隐藏真实IP的目的,又能减少单个IP访问的频率,提升爬虫的可靠性。
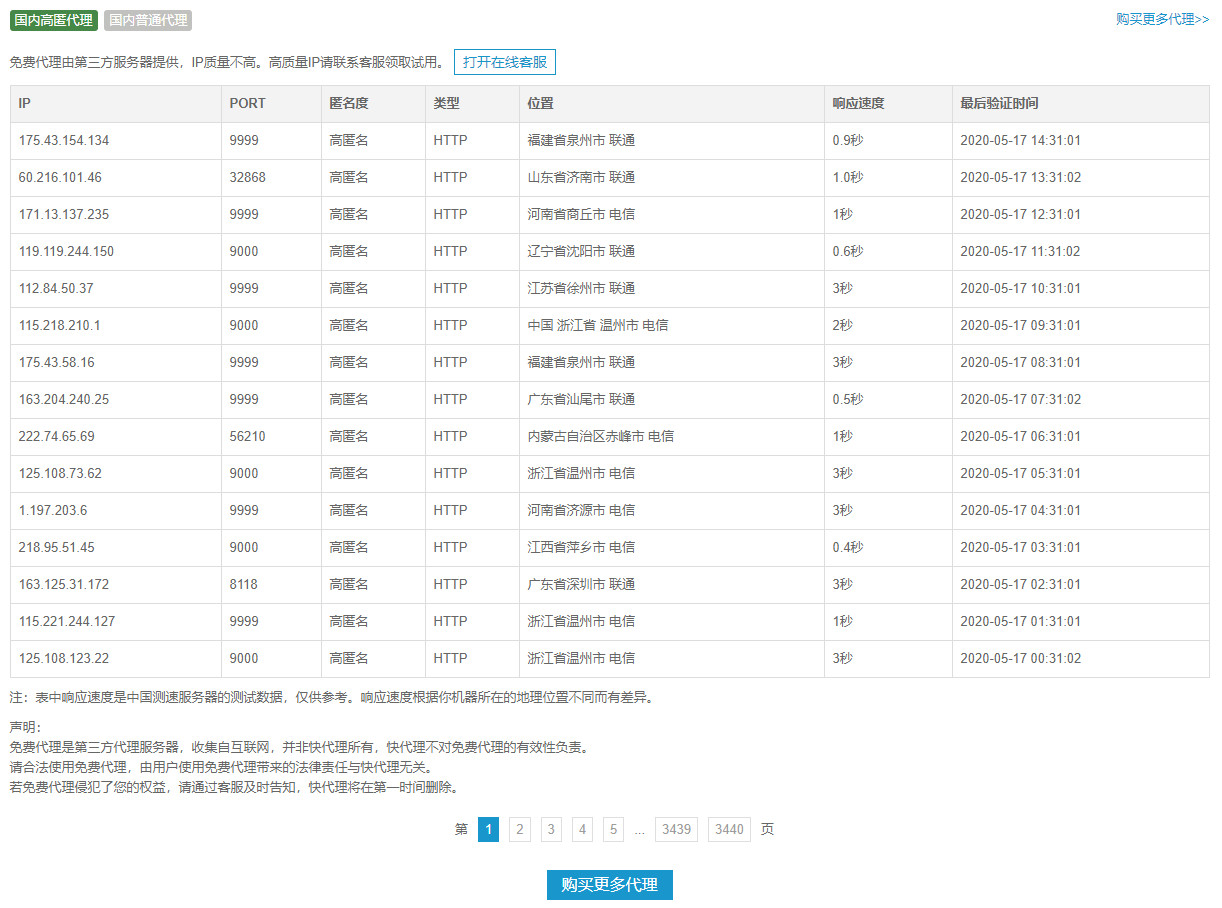
实际上市面上早就有这样的服务啦,有钱的娃,可以直接找一些付费的平台购买,购买后商家会提供海量可用的代理IP。然而谁叫我们是资深叼丝呢,哈哈哈~好在网上有很多平台都提供了免费的代理IP可用,我们只需要充分发挥我们薅羊毛的精神,写一个脚本,将这些代理IP爬下来,然后将有效的代理IP存储到我们的数据库中,并且定期检测代理IP的有效性,这样一个代理IP池就算有了。
IP代理池基本设计原理
我这边做的IP代理池主要是开了三个子进程,两个队列用于进程间的通信。
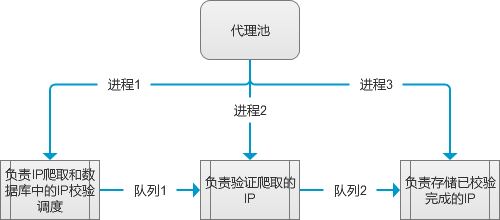
进程1:相当于程序的核心调度模块,负责定时校验数据库中已有的代理IP的可用性,将不可用的删除,可用的进行更新。校验完成后判断数据库中已有的代理IP数量是否满足我们的预期,不满足则启动爬虫,爬取免费代理并放到队列1中。
进程2:负责从队列1中取代理IP,然后进行验证,主要验证可用性、匿名程度、是否支持HTTPS、国家(判断是否可以翻出去的标准)。并将校验没问题的代理IP放到队列2中。
进程3:负责从队列2中取已经校验好的代理IP,并存储至数据库中。
from multiprocessing import Queue, Process
from spider.ProxySpider import startProxySpider
from verify.Verify import startVerifySpider
from db.SaveProxies import saveProxy
from Config import VERIFY_SPIDER_QUEUE_SIZE
if __name__ == "__main__":
q1 = Queue(maxsize=VERIFY_SPIDER_QUEUE_SIZE)
q2 = Queue()
p1 = Process(target=startProxySpider, args=(q1, ))
p2 = Process(target=startVerifySpider, args=(q1, q2))
p3 = Process(target=saveProxy, args=(q2, ))
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
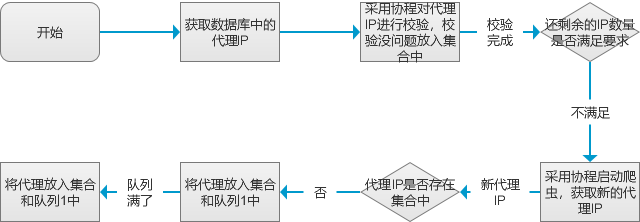
IP代理池的调度模块设计
我这烂大街的代码水印,就谈不上调度模块了哈~其实就是设置一个死循环,循环调度已有代理IP的校验和新代理IP的爬取工作,每隔一段时间执行一次。基本流程如下:
# coding='utf-8'
from gevent import monkey
monkey.patch_all()
from db.DbOperate import DbOperate
# from db.DbOperate import db_operate
import os, time, gevent
from verify.Verify import verifyDb
from spider.HtmlParse import HtmlParse
from Config import sourceLists, VERIFY_DB_GEVENT_SIZE, MIN_VALID_NUMBER, MAX_SPIDER_TASK, UPDATE_TIME, QUEUE_FULL_SLEEP_TIME
# db_operate = DbOperate()
def startProxySpider(queue):
# if(os.path.exists("/home/meetup/Desktop/db.sqlite3")):
# ProxySpider(queue).run()
# else:
# db_operate.create_table()
# db_operate.init_data()
# ProxySpider(queue).run()
ProxySpider(queue).run()
class ProxySpider(object):
proxies_set = set()
def __init__(self, queue):
self.queue = queue
def run(self):
while(True):
db_operate = DbOperate()
self.proxies_set.clear()
db_proxies = db_operate.get()
spawns = []
for proxy in db_proxies:
spawns.append(gevent.spawn(verifyDb, proxy.id, proxy.ip, proxy.port, proxy.type, self.proxies_set))
if(len(spawns) >= VERIFY_DB_GEVENT_SIZE):
gevent.joinall(spawns)
spawns= []
gevent.joinall(spawns)
if(len(self.proxies_set) < MIN_VALID_NUMBER):
spawns = []
for source in sourceLists:
spawns.append(gevent.spawn(self.spider, source))
if(len(spawns) >= MAX_SPIDER_TASK):
gevent.joinall(spawns)
spawns= []
gevent.joinall(spawns)
time.sleep(UPDATE_TIME)
def spider(self, source):
html_parse = HtmlParse()
proxylist = getattr(html_parse, source['function'], None)(source)
if(len(proxylist) != 0):
for proxy in proxylist:
proxy_to_str = '%s:%s' % (proxy['ip'], proxy['port'])
if(proxy_to_str not in self.proxies_set):
self.proxies_set.add(proxy_to_str)
if(self.queue.full()):
time.sleep(QUEUE_FULL_SLEEP_TIME)
else:
self.queue.put(proxy)
免费代理IP的来源及爬取
本项目刚写的时候,我就已经找了十几个提供免费代理IP的网站。而且为了之后支持更多免费代理IP网站,我这里将这些网站的免费代理IP对应的URL,爬取此网站需要用到的函数名,解析此网页用到的xpath规则,以及代理IP来源做成了配置文件,方便以后随时增加新的站点。
sourceLists = [
{
"urls": ["https://www.kuaidaili.com/ops/proxylist/%s/" % n for n in range(1, 11)],
"function": "GeneralXpath",
"decode": "default",
"pattern": "//div[@id='freelist']//tbody[@class='center']//tr",
"position": {"ip": "./td[@data-title='IP']/text()", "port": "./td[@data-title='PORT']/text()", "area": "./td[@data-title='位置']/text()"},
"origin": "kuaidaili",
},
# 代理质量太垃圾
# {
# # 仅取了前10页
# "urls": ["https://www.xicidaili.com/%s/%s % (m, n)" for m in ['nn', 'nt', 'wn', 'wt'] for n in range(1, 11)],
# "function": "GeneralXpath",
# "decode": "default",
# "pattern": "//table[@id='ip_list']//tr[position()>1]",
# "position": {"ip": "./td[2]/text()", "port": "./td[3]/text()", "area": "./td[4]/a/text()"},
# "origin": "xicidaili",
# },
# 此站点已无法访问
# {
# "urls": ["http://www.swei360.com/free/?stype=%s&page=%s" % (m, n) for m in range(1, 5) for n in range(1, 8)],
# "function": "GeneralXpath",
# "decode": "default",
# "pattern": "//tbody/tr",
# "position": {"ip": "./td[1]/text()", "port": "./td[2]/text()", "area": ""},
# "origin": "swei360",
# },
# PhantomJSXpath配置
# {
# # 仅取前20页
# "urls": ["http://www.66ip.cn/%s.html" % n for n in range(1, 21)],
# "function": "PhantomJSXpath",
# "decode": "default",
# "pattern": "//tr[position()>1]",
# "position": {"ip": "./td[1]/text()", "port": "./td[2]/text()", "area": "./td[3]/text()"},
# "origin": "66ip",
# },
{
# 仅取前20页
"urls": ["http://www.66ip.cn/%s.html" % n for n in range(1, 21)],
"function": "GeneralXpath",
"decode": "apparent_encoding",
"pattern": "//tr[position()>1]",
"position": {"ip": "./td[1]/text()", "port": "./td[2]/text()", "area": "./td[3]/text()"},
"origin": "66ip",
},
{
"urls": ["http://www.66ip.cn/areaindex_%s/1.html" % n for n in range(1, 35)],
"function": "GeneralXpath",
"decode": "apparent_encoding",
"pattern": "//tr[position()>1]",
"position": {"ip": "./td[1]/text()", "port": "./td[2]/text()", "area": "./td[3]/text()"},
"origin": "66ip",
},
{
"urls": ["http://www.ip3366.net/?stype=1&page=%s" % n for n in range(1, 11)],
"function": "GeneralXpath",
"decode": "apparent_encoding",
"pattern": "//tbody/tr",
"position": {"ip": "./td[1]/text()", "port": "./td[2]/text()", "area": "./td[6]/text()"},
"origin": "ip3366",
},
{
"urls": ["http://www.ip3366.net/free/?stype=%s&page=%s" % (m, n) for m in range(1, 5) for n in range(1, 8)],
"function": "GeneralXpath",
"decode": "apparent_encoding",
"pattern": "//tbody/tr",
"position": {"ip": "./td[1]/text()", "port": "./td[2]/text()", "area": "./td[5]/text()"},
'origin': 'ip3366',
},
{
# 总共29页,仅取前20页
"urls": ["http://www.89ip.cn/index_%s.html" % n for n in range(1, 51)],
"function": "GeneralXpath",
"decode": "default",
"pattern": "//tbody/tr",
"position": {"ip": "./td[1]/text()", "port": "./td[2]/text()", "area": "./td[3]/text()"},
"origin": "89ip",
},
{
# 刷新会变化
# "urls": ["http://www.data5u.com/%s" % n for n in ["", "free/index.html", "free/gngn/index.shtml", "free/gnpt/index.shtml", "free/gwgn/index.shtml", "free/gwpt/index.shtml"]],
"urls": ["http://www.data5u.com/"],
"function": "Data5u",
"origin": "data5u",
},
{
# 刷新会变化
"urls": ["http://www.goubanjia.com/"],
'function': 'GouBanJia',
'origin': 'goubanjia',
},
# 垃圾,经常出现服务器错误
# {
# # 仅提取前10页
# "urls": ["http://ip.jiangxianli.com/?page=%s" % n for n in range(1, 11)],
# "function": "GeneralXpath",
# "decode": "default",
# "pattern": "//tbody/tr",
# "position": {"ip": "./td[2]/text()", "port": "./td[3]/text()", "area": "./td[6]/text()"},
# "origin": "jiangxianli",
# },
{
"urls": ["http://www.feiyiproxy.com/?page_id=1457"],
"function": "GeneralXpath",
"decode": "default",
"pattern": "//table[not(@*)]//tr[position()>1]",
"position": {"ip": "./td[1]/text()", "port": "./td[2]/text()", "area": "./td[5]/text()"},
"origin": "feiyiproxy",
},
# 已失效
# {
# "urls": ["https://proxy.357.im/?page=%s" % n for n in range(1, 8)],
# "function": "GeneralXpath",
# "decode": "default",
# "pattern": "//tbody/tr",
# "position": {"ip": "./td[1]/text()", "port": "./td[2]/text()", "area": ""},
# "origin": "proxy.357.im",
# },
{
"urls": ["http://www.kxdaili.com/dailiip/%s/%s.html" % (m, n) for m in range(1, 3) for n in range(1, 5)],
"function": "GeneralXpath",
"decode": "apparent_encoding",
"pattern": "//tbody/tr",
"position": {"ip": "./td[1]/text()", "port": "./td[2]/text()", "area": "./td[6]/text()"},
'origin': 'kxdaili',
},
# https://www.zdaye.com/FreeIPList.html
# http://www.xsdaili.com/
]
按道理来讲,应该每个站点配一个爬虫和解析函数。但是我实际在写代码的过程中发现其实大多数的站点的免费代理都是以一个表格的形式提供的,而且基本没什么反爬虫措施。所以针对这类通用的网站,我写了一个通用的方法GeneralXpath来处理。至于其他有反爬虫措施的基本都是单独写一个方法处理,而且为了之后懒得研究,还写了一个Selenium + PhantomJS的方法,遇到搞不定的直接用这个上,哈哈哈~
# coding='utf-8'
from user_agent.UserAgent import UserAgent
import requests, random, time
from lxml import etree
from selenium import webdriver
from db.DbOperate import DbOperate
from Config import SPIDER_REQUESTS_TIMEOUT, SPIDER_RETRY_NUMBER
user_agent = UserAgent()
# db_operate = DbOperate()
class HtmlParse(object):
def __init__(self):
self.headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
def GeneralXpath(self, source):
db_operate = DbOperate()
proxyList = []
for url in source['urls']:
# print('开始URL:%s' % url)
self.headers['UserAgent'] = user_agent.get_pc_ua()
for n in range(1, SPIDER_RETRY_NUMBER + 1):
try:
# print('开始第%d次用代理下载页面' % n)
get_proxies = db_operate.get(country='国内', type='HTTPS', hidden='匿名')
# random_proxy = random.choice(get_proxies)
random_proxy = get_proxies[0]
real_proxy = {'http': random_proxy.ip + ':' + random_proxy.port, 'https': random_proxy.ip + ':' + random_proxy.port}
res = requests.get(url, headers=self.headers, proxies=real_proxy, timeout=SPIDER_REQUESTS_TIMEOUT)
except Exception as e:
res = ''
# print(Exception, ':', e)
else:
# print('第%d次代理下载页面成功' % n)
break
if(res == ''):
try:
# print('开始用真实IP下载页面')
res = requests.get(url, headers=self.headers, timeout=SPIDER_REQUESTS_TIMEOUT)
except requests.exceptions.ConnectTimeout:
res = ''
except Exception as e:
res = ''
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), url, ':', Exception, e)
if(res):
if(source['decode'] == 'default'):
selector = etree.HTML(res.text)
elif(source['decode'] == 'apparent_encoding'):
selector = etree.HTML(res.content.decode(res.apparent_encoding))
lists = selector.xpath(source['pattern'])
for content in lists:
proxy = {'ip':'', 'port':'', 'origin':source['origin']}
try:
proxy['ip'] = content.xpath(source['position']['ip'])[0].strip()
proxy['port'] = content.xpath(source['position']['port'])[0].strip()
if(source['position']['area']):
try:
proxy['area'] = content.xpath(source['position']['area'])[0].strip()
except:
proxy['area'] = ''
if((proxy['ip'] != '') and (proxy['port'] != '')):
proxyList.append(proxy)
else:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '%s的解析规则可能改变了!-为空' % source['origin'])
continue
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), url, '解析异常:', Exception, ':', e)
continue
return proxyList
def PhantomJSXpath(self, source):
proxyList = []
proxy = {'ip':'', 'port':'', 'origin':source['origin']}
driver = webdriver.PhantomJS(executable_path="/home/phantomjs/bin/phantomjs")
for url in source['urls']:
# print('开始URL:%s' % url)
for n in range(1, SPIDER_RETRY_NUMBER + 1):
try:
# print('开始第%d次用真实IP下载页面' % n)
driver.get(url)
except Exception as e:
res = False
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), url, ':', Exception, e)
# print('第%d次真实IP下载页面异常' % n)
else:
res = True
# print('第%d次真实IP下载页面成功' % n)
break
if(res):
time.sleep(5)
selector = etree.HTML(driver.page_source)
lists = selector.xpath(source['pattern'])
for content in lists:
proxy = {'ip':'', 'port':'', 'origin':source['origin']}
try:
proxy['ip'] = content.xpath(source['position']['ip'])[0]
proxy['port'] = content.xpath(source['position']['port'])[0]
if(source['position']['area']):
try:
proxy['area'] = content.xpath(source['position']['area'])[0].strip()
except:
proxy['area'] = ''
if((proxy['ip'] != '') and (proxy['port'] != '')):
proxyList.append(proxy)
else:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '%s的解析规则可能改变了!-为空' % source['origin'])
continue
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), url, '解析异常:', Exception, ':', e)
continue
driver.quit()
return proxyList
def Data5u(self, source):
db_operate = DbOperate()
proxyList = []
for url in source['urls']:
# print('开始URL:%s' % url)
self.headers['UserAgent'] = user_agent.get_pc_ua()
for n in range(1, SPIDER_RETRY_NUMBER + 1):
try:
# print('开始第%d次用代理下载页面' % n)
get_proxies = db_operate.get(country='国内', type='HTTPS', hidden='匿名')
# random_proxy = random.choice(get_proxies)
random_proxy = get_proxies[0]
real_proxy = {'http': random_proxy.ip + ':' + random_proxy.port, 'https': random_proxy.ip + ':' + random_proxy.port}
res = requests.get(url, headers=self.headers, proxies=real_proxy, timeout=SPIDER_REQUESTS_TIMEOUT)
except Exception as e:
res = ''
# print(Exception, ':', e)
else:
# print('第%d次代理下载页面成功' % n)
break
if(res == ''):
try:
# print('开始用真实IP下载页面')
res = requests.get(url, headers=self.headers, timeout=SPIDER_REQUESTS_TIMEOUT)
except requests.exceptions.ConnectTimeout:
res =''
except Exception as e:
res = ''
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), url, ':', Exception, e)
if(res):
selector = etree.HTML(res.text)
lists = selector.xpath('//ul[@class="l2"]')
for content in lists:
proxy = {'ip':'', 'port':'', 'origin':source['origin']}
try:
proxy['ip'] = content.xpath('./span[1]/li/text()')[0]
# port = proxy.xpath('./span[2]/li/text()')[0]
port_class = content.xpath('./span[2]/li/@class')[0]
port_class = port_class.split(' ')[1]
port = port_class.replace('A', '0').replace('B', '1').replace('C', '2').replace('D', '3').replace('E', '4').replace('F', '5').replace('G', '6').replace('H', '7').replace('I', '8').replace('Z', '9')
proxy['port'] = int(int(port) / 8)
try:
proxy['area'] = proxy.xpath('./span[6]/li/text()')[0]
except:
proxy['area'] = ''
if((proxy['ip'] != '') and (proxy['port'] != '')):
proxyList.append(proxy)
# print(proxy)
else:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '%s的解析规则可能改变了!-为空' % source['origin'])
continue
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), url, ':', Exception, ':', e)
continue
return proxyList
def GouBanJia(self, source):
db_operate = DbOperate()
proxyList = []
for url in source['urls']:
# print('开始URL:%s' % url)
self.headers['UserAgent'] = user_agent.get_pc_ua()
for n in range(1, SPIDER_RETRY_NUMBER + 1):
try:
# print('开始第%d次用代理下载页面' % n)
get_proxies = db_operate.get(country='国内', type='HTTPS', hidden='匿名')
# random_proxy = random.choice(get_proxies)
random_proxy = get_proxies[0]
real_proxy = {'http': random_proxy.ip + ':' + random_proxy.port, 'https': random_proxy.ip + ':' + random_proxy.port}
res = requests.get(url, headers=self.headers, proxies=real_proxy, timeout=SPIDER_REQUESTS_TIMEOUT)
except Exception as e:
res = ''
# print(Exception, ':', e)
else:
# print('第%d次代理下载页面成功' % n)
break
if(res == ''):
try:
# print('开始用真实IP下载页面')
res = requests.get(url, headers=self.headers, timeout=SPIDER_REQUESTS_TIMEOUT)
except requests.exceptions.ConnectTimeout:
res = ''
except Exception as e:
res = ''
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), url, ':', Exception, e)
if(res):
selector = etree.HTML(res.text)
lists = selector.xpath('//tbody/tr')
for content in lists:
proxy = {'ip':'', 'port':'', 'origin':source['origin']}
try:
ex_ips = content.xpath('./td[@class="ip"]/*[contains(@style, "none")]')
for ex_ip in ex_ips:
parent = ex_ip.getparent()
parent.remove(ex_ip)
ips = content.xpath('./td[@class="ip"]/*/text()')
ip = ''
for i in ips:
ip = ip + i
port = ips[-1]
l = len(port)
proxy['ip'] = ip[0: -l]
port_class = content.xpath('./td[@class="ip"]/span[last()]/@class')[0]
port_class = port_class.split(' ')[1]
port = port_class.replace('A', '0').replace('B', '1').replace('C', '2').replace('D', '3').replace('E', '4').replace('F', '5').replace('G', '6').replace('H', '7').replace('I', '8').replace('Z', '9')
proxy['port'] = int(int(port) / 8)
try:
proxy['area'] = "".join(proxy.xpath('./td[4]/a/text()'))
except:
proxy['area'] = ''
if((proxy['ip'] != '') and (proxy['port'] != '')):
proxyList.append(proxy)
# print(proxy)
else:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '%s的解析规则可能改变了!-为空' % source['origin'])
continue
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), url, ':', Exception, ':', e)
continue
return proxyList
免费代理IP网站,常见的反爬虫措施
实际上大部分网站都是没做反爬虫的,因为可能那些商家也知道我们想干嘛,懒得防了,哈哈哈~然而还是有几个站点,做了点简单防护的。这里简单介绍下原理,算是涨点发爬虫经验吧!
第一种:HTML混淆
这个网站http://www.goubanjia.com/采用了HTML混淆的方式(虽然混淆了,后面经验证,此网站的代理可用度还可以)。此类混淆主要有两个特征:
- HTML中混有大量的隐藏元素,隐藏元素中有的有值有的为空。这些隐藏元素的标签不固定,可能为div,也可能为p标签等。而且隐藏元素的个数和位置都不固定;
- IP地址并非在一个元素中,而是分布在多个元素中,且这些元素的位置也不固定;
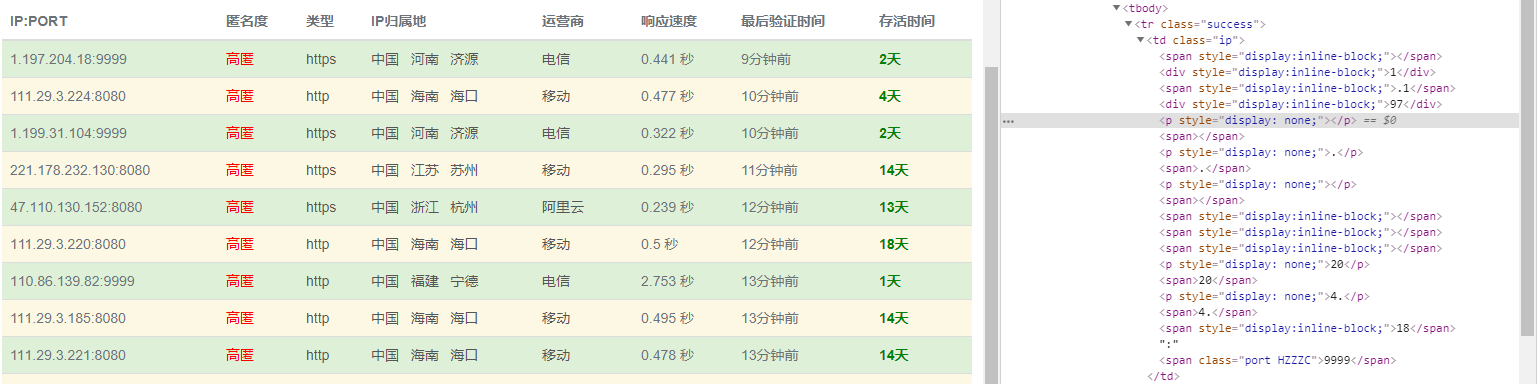
这样一来想使用正则解析,基本不可能了,因为毫无规则可言!所以只能选Xpath解析或者BeautifulSoup解析。由于隐藏标签使用了行内样式,给我们的突破工作降低了一些难度(其实也没什么难度,哈哈哈),所以这里我选用了Xpath解析,并且采用了最笨的方法进行了突破(有好方法欢迎留言,让我也学习学习)。其原理就是:利用Xpath找到所有style包含none的节点,然后找到这些节点的父节点,并从父节点中删除此隐藏节点。然后从清理完隐藏元素的节点中解析出所有文本内容,并将文本内容拼接在一起即可。对应核心代码如下:
ex_ips = content.xpath('./td[@class="ip"]/*[contains(@style, "none")]')
for ex_ip in ex_ips:
parent = ex_ip.getparent()
parent.remove(ex_ip)
ips = content.xpath('./td[@class="ip"]/*/text()')
ip = ''
for i in ips:
ip = ip + i
port = ips[-1]
l = len(port)
proxy['ip'] = ip[0: -l]
第二种:js混淆加密
这个网站http://www.data5u.com/采用了js加密代理IP端口号的方式,请求初次返回的HTML中的端口号和实际网页中显示的不一样。还好在写测试的时候和网页对比了一下,要不然就忽略了这个细节。


经过一顿分析,发现HTML中端口号处有一串可疑的字符串,怀疑端口号应该是页面加载完成后,用js计算替换上来的。找一下就发现了一个可疑js,但是此js还稍微进行了混淆,根本不打算让人读,对应原始js如下:
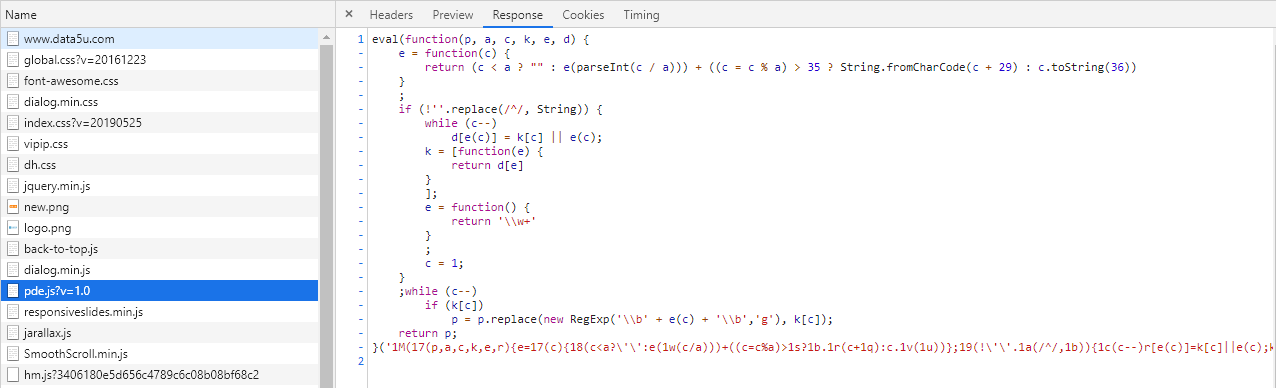
下面使用js将这段晦涩的js转换为我们可以看懂的js,对应的转换代码如下:
<html>
<head></head>
<body>
<script type="text/code-template" id="functionBody">
$(function() {
$(_$[0])[_$[1]](function() {
var a = $(this)[_$[2]]();
if (a[_$[3]](_$[4]) != -0x1) {
return
};
var b = $(this)[_$[5]](_$[6]);
try {
b = (b[_$[7]](_$[8]))[0x1];
var c = b[_$[7]](_$[9]);
var d = c[_$[10]];
var f = [];
for (var g = 0x0; g < d; g++) {
f[_$[11]](_$[12][_$[3]](c[g]))
};
$(this)[_$[2]](window[_$[13]](f[_$[14]](_$[15])) >> 0x3)
} catch(e) {}
})
})
</script>
<script type="text/javascript">
var _$ = ['\x2e\x70\x6f\x72\x74', "\x65\x61\x63\x68", "\x68\x74\x6d\x6c", "\x69\x6e\x64\x65\x78\x4f\x66", '\x2a', "\x61\x74\x74\x72", '\x63\x6c\x61\x73\x73', "\x73\x70\x6c\x69\x74", "\x20", "", "\x6c\x65\x6e\x67\x74\x68", "\x70\x75\x73\x68", '\x41\x42\x43\x44\x45\x46\x47\x48\x49\x5a', "\x70\x61\x72\x73\x65\x49\x6e\x74", "\x6a\x6f\x69\x6e", ''];
let functionBody = document.getElementById("functionBody").innerHTML;
let readableFunctionBody = functionBody.replace(/_\$\[[0-9]+\]/g, x => "'" + eval(x) + "'");
document.write(readableFunctionBody);
</script>
</body>
</html>
转换后这个加密逻辑就很清晰了,原理就是将HTML中端口号处的可疑字符串拿出来,然后在字符串“ABCDEFGHIZ”中找位置坐标,将所有的位置坐标拼接起来除以8,即可得到最终的端口后。对应的转换后的js如下:
$(function() {
$('.port')['each'](function() {
var a = $(this)['html']();
if (a['indexOf']('*') != -0x1) {
return
};
var b = $(this)['attr']('class');
try {
b = (b['split'](' '))[0x1];
var c = b['split']('');
var d = c['length'];
var f = [];
for (var g = 0x0; g < d; g++) {
f['push']('ABCDEFGHIZ' ['indexOf'](c[g]))
};
$(this)['html'](window['parseInt'](f['join']('')) >> 0x3)
} catch(e) {}
})
})
知道了原理,我们就可以利用Python实现这个加密算法了,其实直接进行字符串替换就可以了:
port = port_class.replace('A', '0').replace('B', '1').replace('C', '2').replace('D', '3').replace('E', '4').replace('F', '5').replace('G', '6').replace('H', '7').replace('I', '8').replace('Z', '9')
proxy['port'] = int(int(port) / 8)
代理IP的有效性及匿名程度校验
代理IP的验证,我这里分为数据库中已存IP的验证和新爬取的IP的验证。对于新爬取的代理IP验证,主要验证其可用性,是否支持HTTPS、匿名程度、是否可以翻出去。而对于数据库中的代理IP直接验证可用性即可。
有效性验证
先请求HTTP网站,如果请求有效,表示此代理是可用的。然后再请求HTTPS网站,如果有效,表示此代理IP支持HTTPS。这里的HTTP网站选用的是站长之家,HTTPS网站选用的是百度。
def verifyValid(ip, port, types):
headers = {"User-Agent": user_agent.get_pc_ua()}
proxy = {'http': str(ip) + ':' + str(port), 'https': str(ip) + ':' + str(port)}
urls = {'http':VERIFY_HTTP_URL, 'https':VERIFY_HTTPS_URL}
try:
start = time.time()
res = requests.get(urls[types.lower()], headers=headers, proxies=proxy, timeout=VERIFY_SPIDER_REQUESTS_TIMEOUT)
speed = round(time.time() - start, 2)
except:
return {'status': False}
else:
if(res.status_code == 200):
return {'status': True, 'speed': speed}
else:
return {'status': False}
匿名程度验证
对于匿名程度的验证,采用的是开源接口http://httpbin.org/get,此接口可返回各种你想要的请求信息和响应信息,并且有单独的HTTP和HTTPS接口。只需要设置好代理,请求此接口,并解析响应的json文件,即可得知此代理IP的匿名程度。
- 如果origin中包含自己真实的IP,则为透明代理;
- 如果响应中包含Proxy-Connection参数,则为匿名代理;
- 其他情况则为高匿代理;
验证匿名程度的方法中,我还加入了代理IP的城市信息的补充,因为有些网站提供的免费代理IP不带位置信息。我这里为了后续管理更加完善,引入了Geo IP对代理IP的国家和城市进行查询和补充。Geo IP相当于超级大的数据库,并做了查询优化(使用的二进制文件),保证查询的效率。可以通过此库查询代理IP的很多信息。
def verifyHiddenCountryArea(ip, port, area):
headers = {"User-Agent": user_agent.get_pc_ua()}
proxy = {'http': str(ip) + ':' + str(port), 'https': str(ip) + ':' + str(port)}
'''
for n in range(1, VERIFY_HIDDEN_RETRY_NUMBER + 1):
try:
res = requests.get(VERIFY_HIDDEN_URL, headers=headers, proxies=proxy, timeout=VERIFY_SPIDER_REQUESTS_TIMEOUT)
try:
response = res.json()
except:
response = False
continue
except requests.exceptions.ConnectTimeout:
response = False
except requests.exceptions.ProxyError:
response = False
except requests.exceptions.ReadTimeout:
response = False
except Exception as e:
response = False
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '验证匿名程度的API可能失效了: ', Exception, ':', e)
else:
break
'''
try:
res = requests.get(VERIFY_HIDDEN_URL, headers=headers, proxies=proxy, timeout=VERIFY_SPIDER_REQUESTS_TIMEOUT)
try:
response = res.json()
except:
response = False
except requests.exceptions.ConnectTimeout:
response = False
except requests.exceptions.ProxyError:
response = False
except requests.exceptions.ReadTimeout:
response = False
except Exception as e:
response = False
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '验证匿名程度的API可能失效了: ', Exception, ':', e)
if(not response):
return {'status': False}
origin_ip = response.get('origin', '')
proxy_connection = response['headers'].get('Proxy-Connection', None)
# 透明
if(MY_IP in origin_ip):
hidden = '透明'
# 匿名
elif(proxy_connection or MY_IP not in origin_ip):
hidden = '匿名'
# 高匿
else:
hidden = '高匿'
try:
response = reader.city(ip)
country = response.country.names['zh-CN']
if(not area):
try:
city = country + response.city.names['zh-CN']
except:
city = country + response.city.name
else:
city = False
if(country == '中国'):
country = '国内'
else:
country = '国外'
except:
country = False
city = False
# # IP地址不合法
# except ValueError as value_error:
# print(value_error)
# # 数据库中无此IP地址
# except AddressNotFoundError as notfound_error:
# print(notfound_error)
# # geoip bug
# except maxminddb.InvalidDatabaseError as geoip_bug:
# print(geoip_bug)
return {'status': True, 'hidden': hidden, 'country': country, 'city': city}
验证是否可访问国外站点
这里选择了一个墙外的HTTP站点http://digg.com/进行校验,如果请求有效,表示可翻出去。
def verifySpiderCountry(ip, port):
headers = {"User-Agent": user_agent.get_pc_ua()}
proxy = {'http': str(ip) + ':' + str(port), 'https': str(ip) + ':' + str(port)}
try:
# 稳定的墙外http站点验证
res = requests.get(VERIFY_COUNTRY_URL, headers=headers, proxies=proxy, timeout=VERIFY_SPIDER_REQUESTS_TIMEOUT)
except:
return '国内'
else:
return '国外'
代理IP的存储及更新
为了方便存储和后续的扩展,我这里采用orm连接mysql的方式,进行有效代理IP的存储。如果大家有需要改为其他数据库,只需要改写里面的数据库连接部分即可。这也是orm的好处,一套代理可适应多种数据库。这里采用的是sqlalchemy库进行orm操作,sqlalchemy做的事情就是把关系型数据库的表结构映射到对象上,然后以对象的形式取操作数据库,而且适配了多种关系型数据库,对于新手来说是很容易操作和理解的。
# coding='utf-8'
from sqlalchemy import Column, Integer, String, VARCHAR, DateTime, Numeric, create_engine, ForeignKey
# from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.exc import IntegrityError
# from sqlalchemy.sql.expression import func
import os, datetime
import warnings
import time
# 忽略sqlalchemy警告
warnings.filterwarnings("ignore")
# 创建对象的基类:
BaseModel = declarative_base()
# 定义代理对象:
class Proxy(BaseModel):
# 表的名字:
__tablename__ = 'proxies_proxy'
# 表的结构:
id = Column(Integer, primary_key=True, autoincrement=True)
ip = Column(VARCHAR(16), unique=True, nullable=False)
port = Column(VARCHAR(10), nullable=False)
type = Column(VARCHAR(5), nullable=False)
hidden = Column(VARCHAR(2), nullable=False)
speed = Column(Numeric(5, 2), nullable=False)
country = Column(VARCHAR(2), nullable=False)
area = Column(VARCHAR(100))
origin = Column(VARCHAR(20), nullable=False)
create_time = Column(DateTime(), default=datetime.datetime.utcnow)
update_time = Column(DateTime(), default=datetime.datetime.utcnow, onupdate=datetime.datetime.utcnow)
class DbOperate(object):
def __init__(self):
# 初始化数据库连接:
# self.engine = create_engine('sqlite:////home/meetup/Desktop/db.sqlite3', echo=False, connect_args={'check_same_thread': False})
self.engine = create_engine('mysql+pymysql://local:连接密码@账户:端口/数据库名', echo=False)
# 创建DBSession类型:
self.DBSession = sessionmaker(bind=self.engine)
self.session = self.DBSession()
# print('数据库操作初始化完成')
def create_table(self):
# 创建BaseModel所有子类与数据库的对应关系
# print('开始创建表')
BaseModel.metadata.create_all(self.engine)
# print('创建表完成')
'''
def init_data(self):
# 添加到session:
self.session.add_all([
# 创建新Country对象:
Country(name='国内'),
Country(name='国外'),
# 创建新Type对象:
Type(name='HTTP'),
Type(name='HTTPS'),
# 创建新Hidden对象:
Hidden(name='透明'),
Hidden(name='匿名'),
Hidden(name='高匿'),
])
# 提交即保存到数据库:
self.session.commit()
'''
def drop_db(self):
BaseModel.metadata.drop_all(self.engine)
# country: 国内:1,国外:2; type: HTTP:1,HTTPS:2; hidden: 透明:1,匿名:2,高匿:3;
def get(self, country='', type='', hidden=''):
try:
if(country == '' and type == '' and hidden == ''):
return self.session.query(Proxy.id, Proxy.ip, Proxy.port, Proxy.type).all()
else:
return self.session.query(Proxy).filter(Proxy.country==country, Proxy.type==type, Proxy.hidden==hidden).order_by(Proxy.speed).all()
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '从数据库获取IP失败: ', Exception, ':', e)
self.session.close()
def update(self, id, speed):
try:
proxy = self.session.query(Proxy).get(int(id))
proxy.speed = speed
self.session.commit()
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '更新数据库中的IP失败: ', Exception, ':', e)
self.session.close()
def delete(self, id):
try:
proxy = self.session.query(Proxy).get(int(id))
self.session.delete(proxy)
self.session.commit()
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '删除数据库中的IP失败: ', Exception, ':', e)
self.session.close()
def add(self, proxy):
try:
self.session.add(Proxy(ip=proxy['ip'], port=proxy['port'], type=proxy['type'], hidden=proxy['hidden'], speed=proxy['speed'], country=proxy['country'], area=proxy['area'], origin=proxy['origin']))
self.session.commit()
except IntegrityError:
self.session.close()
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'IP保存至数据库失败: ', Exception, ':', e)
self.session.close()
有了这套orm之后,后续的数据存储和更新就变得很方便。对于数据中的代理IP,验证完可用性后,可用的代理IP只需要更新其速度即可,不可用的代理IP直接删除。
# coding='utf-8'
from db.DbOperate import DbOperate
import time
db_operate = DbOperate()
def saveProxy(queue):
while(True):
try:
# print('开始保存已经验证的代理')
proxy = queue.get()
# print(proxy)
db_operate.add(proxy)
except Exception as e:
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), '保存异常: ', Exception , ':', e)
print(proxy)
# pass
def verifyDb(id, ip, port, types, proxies_set):
db_operate = DbOperate()
for n in range(1, VERIFY_DB_RETRY_NUMBER + 1):
result = verifyValid(ip, port, types)
if(result['status']):
db_operate.update(id, result['speed'])
proxy_to_str = '%s:%s' % (ip, port)
proxies_set.add(proxy_to_str)
break
elif(n == VERIFY_DB_RETRY_NUMBER):
db_operate.delete(id)
IP代理池的管理及调用
我们做完调度、验证和存储后,基本一个高可用的免费IP代理池就完成了。但是只有这么一个看不见的池子也不行,因为我们最终的目的是用它,所以伴随着必不可少的就是有一个接口能随时取出其中的代理IP(按照速度排序获取、仅获取支持HTTPS的代理IP等等)。这里我使用Python中的web框架搭建了一个api可供我在本地和其他服务器中调取。
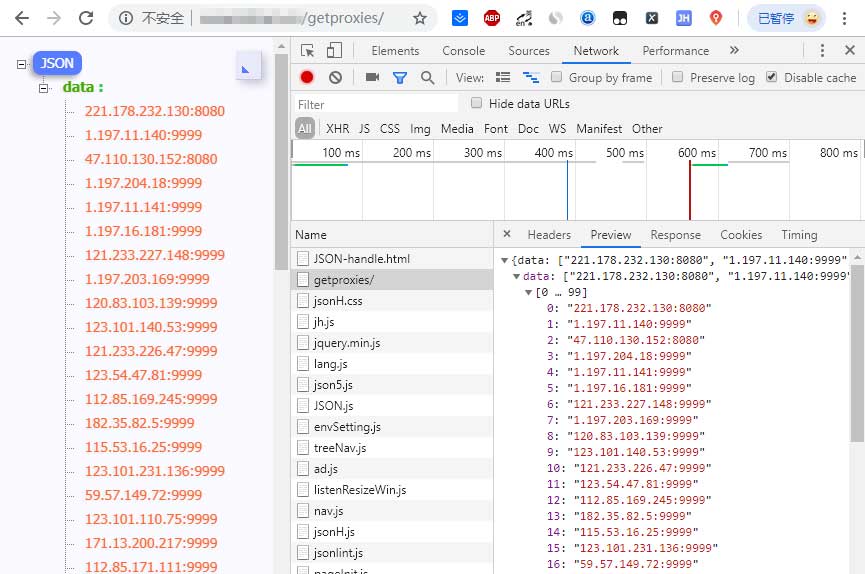
当然如果除了api需求以外,还有管理需求的话,也可以搞个管理界面。有了管理界面后就可以随时查看,增删改查都是OK的。
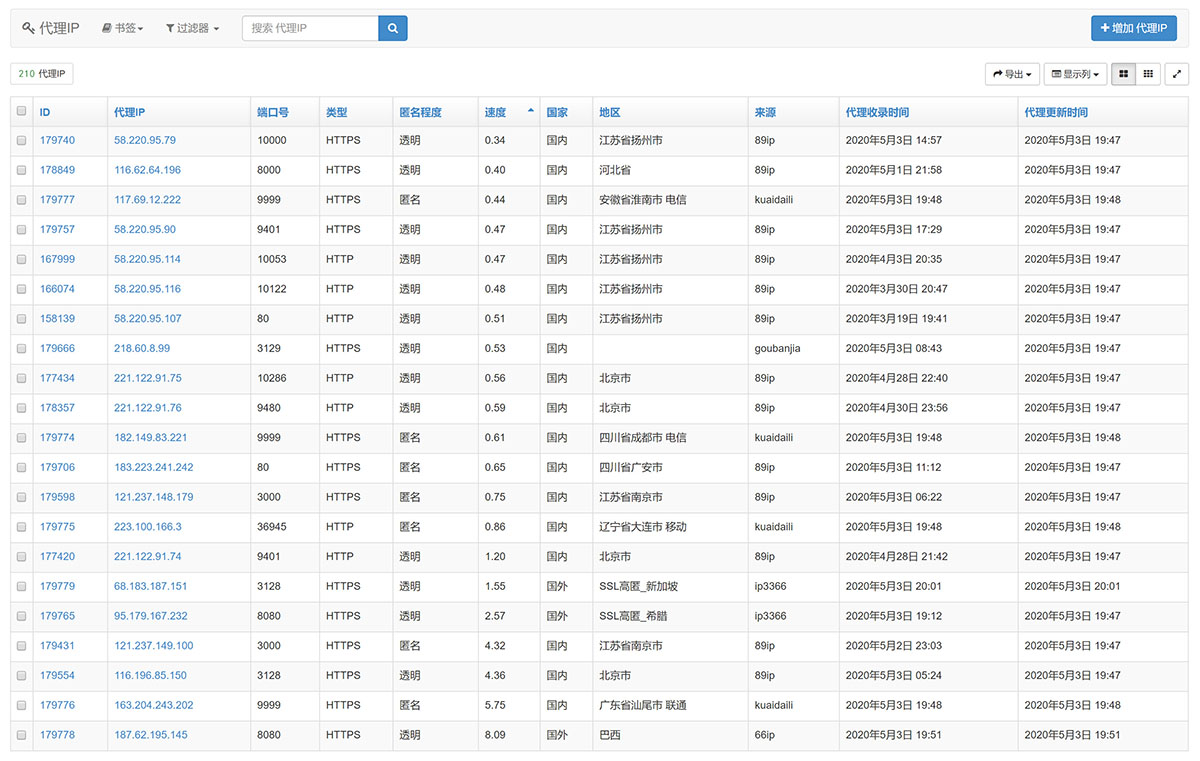
IP代理池完整项目的配置及使用方法
使用前的配置
在DbOperate的数据库初始化中,配置好自己的数据库所在目录。
class DbOperate(object):
def __init__(self):
# 初始化数据库连接:
# self.engine = create_engine('sqlite:////home/meetup/Desktop/db.sqlite3', echo=False, connect_args={'check_same_thread': False})
self.engine = create_engine('mysql+pymysql://local:iMySql@Admin@localhost:3316/imyshare', echo=False)
在Config中配置好自己的真实IP(MY_IP),原因是服务器都是固定IP,所以直接配置,永久使用即可。如果不知道自己的IP地址,可在控制台运行MY_IP.py即可得知自己的真实IP地址。
MY_IP = "xxx.xx.xx.xxx"
如果需要去除已失效的免费代理代理IP来源,直接在Config的sourceLists中直接注释相应的项即可。如果需要新增免费代理IP来源,需要在sourceLists中配置想要的url和对应爬取解析函数名称,如果使用GeneralXpath,还需要配置表格父节点和IP子节点的Xpath规则。如果需要新增爬取解析方法,需要在HtmlParse的HtmlParse类中新增你的方法,并在sourceLists进行配置。
sourceLists = [
{
"urls": ["https://www.kuaidaili.com/ops/proxylist/%s/" % n for n in range(1, 11)],
"function": "GeneralXpath",
"decode": "default",
"pattern": "//div[@id='freelist']//tbody[@class='center']//tr",
"position": {"ip": "./td[@data-title='IP']/text()", "port": "./td[@data-title='PORT']/text()", "area": "./td[@data-title='位置']/text()"},
"origin": "kuaidaili",
},
]
class HtmlParse(object):
def __init__(self):
self.headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
def GeneralXpath(self, source):
db_operate = DbOperate()
proxyList = []
for url in source['urls']:
# print('开始URL:%s' % url)
self.headers['UserAgent'] = user_agent.get_pc_ua()
在Verify中的reader处配置好自己的Geo IP库路径;Geo IP库下载地址:https://dev.maxmind.com/geoip/geoip2/downloadable/#MaxMind_APIs
IP代理池项目依赖库
- geoip2==2.9.0
- gevent==1.3.7
- lxml==4.2.5
- requests==2.18.4
- selenium==2.48.0
- phantomjs==2.1.1
- SQLALchemy==1.2.15
项目运行方法
- 使用命令:nohup python3 -u iMyIPProxy.py > Proxy.log 2>&1 & 即可在Linux服务器中静默运行本项目;
- 如果要实时查看日志文件使用命令:tail -f Proxy.log
- 查看全部输出使用命令:cat Proxy.log
相关资源推荐:
- Python爬虫快速入门,爬虫进阶学习路线,以及爬虫知识体系总结
- 利用Python爬取epubw整站27502本高质量电子书,并自动保存至百度网盘(内附分享)
- 利用Python实现百度网盘自动化:转存分享资源,获取文件列表,重命名,删除文件,创建分享链接等等
- 抖音短视频无水印解析下载,换个角度让爬虫更简单
- 巧办法解析tiktok无水印视频下载地址,轻松搞定tiktok无水视频下载!
- Python利用youtube-dl库快速搭建视频解析下载网站,支持下载1000+网站的视频
- 利用Python打造免费、高可用、高匿名的IP代理池
- 利用Python进行简单的OCR图像识别,解决爬虫中的验证码、图像文字识别等问题