





最近在新增代理池免费代理来源时,遇到了一个有趣的代理网站(蚂蚁代理:http://www.mayidaili.com/free)。此站点在提供免费代理时,代理IP的端口号是以图像的形式展示的。想必就是为了反爬虫了,不过这也难不住我大Python啊,哈哈哈~今天就跟大家分享如何利用python进行简单的图像识别,识别图片中的文字,这里具体就是IP端口号啦。
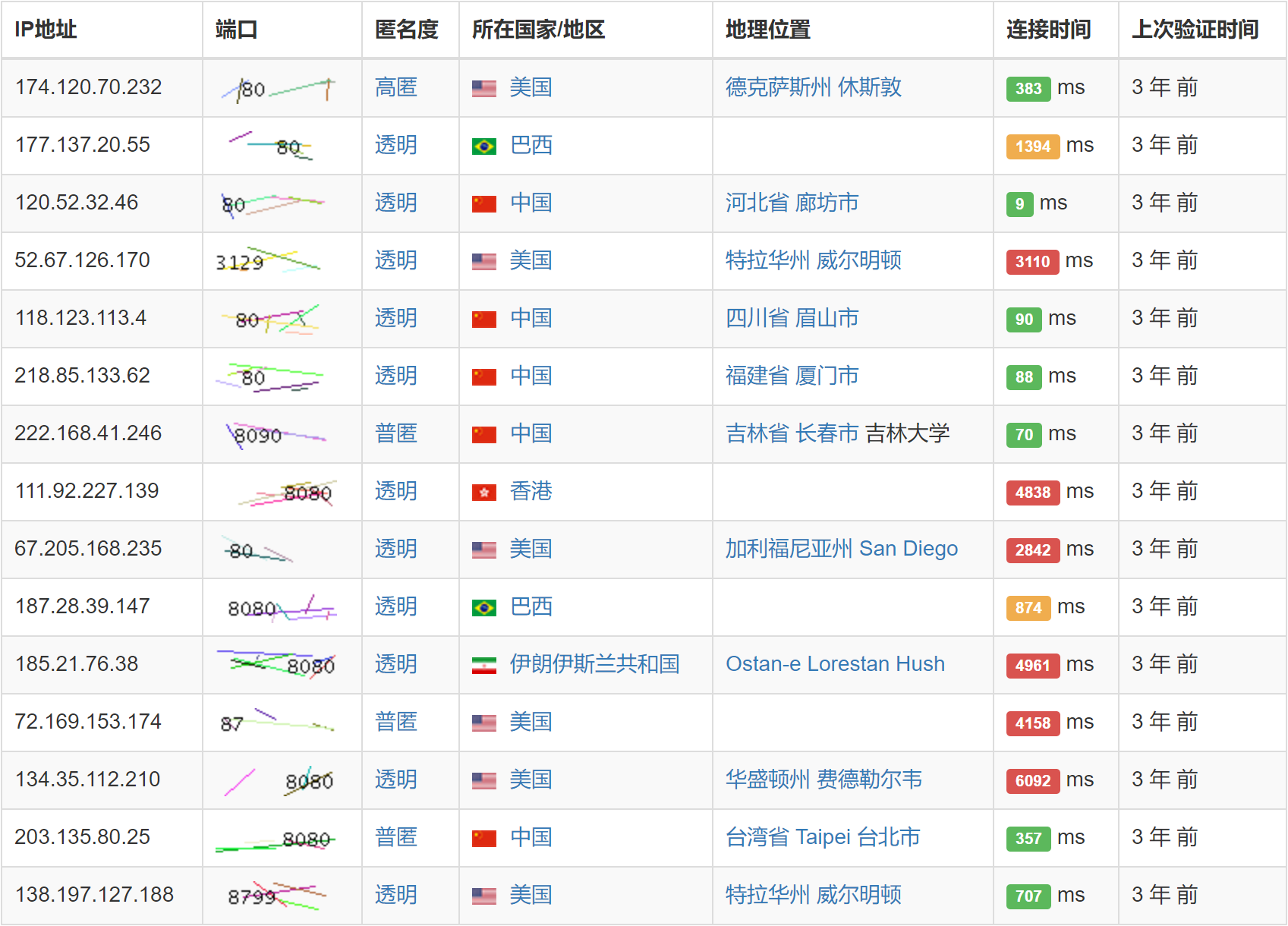
关于免费、高可用、高匿名的IP代理池的搭建可参考我的这篇文章:利用Python打造免费、高可用、高匿名的IP代理池
OCR图像识别必备库
在这里用到的主要库是:Tesseract,Tesseract是由Google赞助的OCR开源库,也是目前开源OCR库里面比较优秀的库之一。况且Google在机器学习、图像处理方面的影响想必就不用多说了吧!
不过Tesseract是一个Python的命令行工具,不能直接导入到我们的代码中去使用。所以我们还需要一个库:pytesseract,在代码中导入此库进行Tesseract的调用。
由于还涉及到图像方面的一点点内容,所以还需要安装一个Pillow,Pillow已经算是Python中图像处理的标准库了,就不做介绍了。
直接使用Tesseract进行图像文字识别
装好必要的库之后,我们直接将蚂蚁代理中的图片下载下来,先进行测试。为了大家看的更清楚,我这里将图片名称改为端口号了。
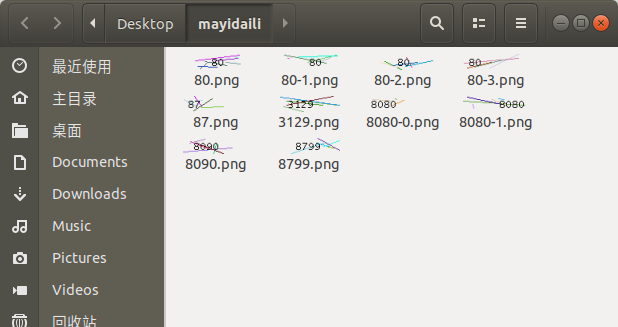
这里只需要几行代码就可以进行简单的文字识别了(人生苦短,我用Python,哈哈哈~),我们初步测试的代码如下:
# 初步测试
images = os.listdir("./mayidaili/")
for image_name in images:
image = Image.open("./mayidaili/%s" % image_name)
result = pytesseract.image_to_string(image)
print("%s的识别结果为:%s" %(image_name, result))
运行一下,然后激动的发现,卧槽,谷歌出品竟然一个都没识别正确!!!哈哈哈~
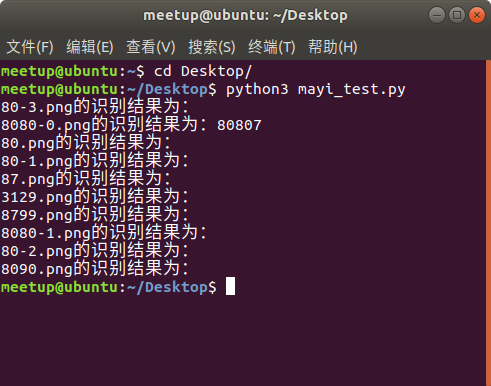
根据图像特征对图像进行预处理
不过我们也不能怪这个库哈,要是这么简单,不是太侮辱对方的反爬虫手段了吗?哈哈哈~那难道我们要去训练Tesseract来提高识别的准确性吗?我这么懒的人,当然不会去花时间干那份体力活啊!而且好歹当年也混了四年电子信息工程专业啊,对数字图像处理还算略知一二的哈(捂脸)。最终经过研究发现,此网站在生成端口号时,应该是先生成的端口号,然后再添加的干扰线,但是有个很大的漏洞就是端口号竟然都是一个颜色的!!基本RGB值都在30以下。
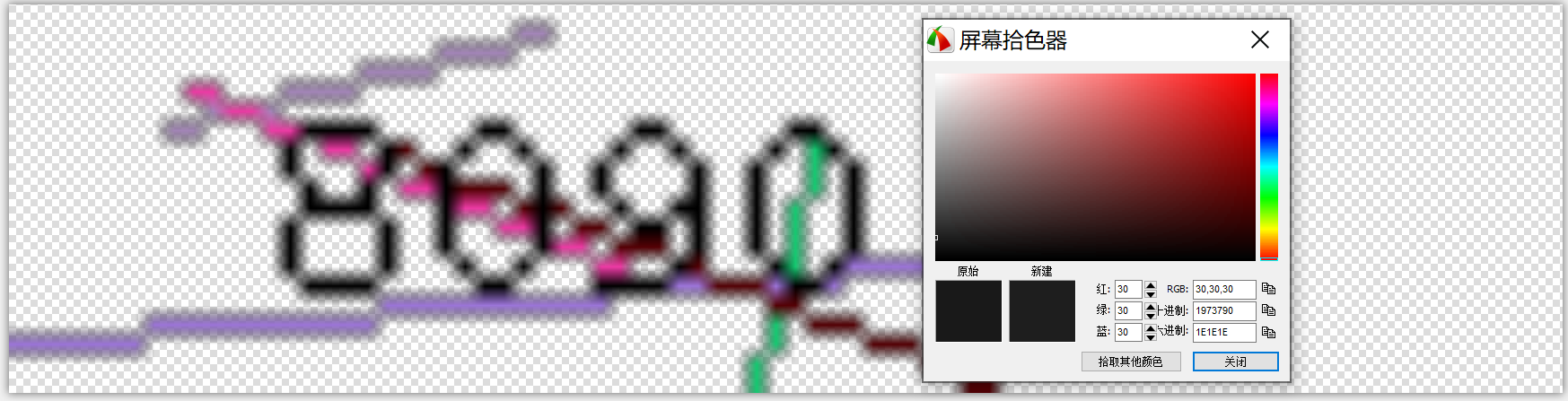
有了这个特征就很方便了啊,我们在调用Tesseract进行识别之前对图像进行预处理,利用颜色值范围,将RGB大于30,或者Alpha为0的像素全部填充为白色,这样就可以完美去掉除了端口号以外所有的干扰信息啦。然后再调用Tesseract去识别预处理后的图像即可。
# 图片预处理
image = Image.open("./mayidaili/80.png")
image.show()
pixdata = image.load()
for y in range(image.size[1]):
for x in range(image.size[0]):
if pixdata[x,y][0]>30 or pixdata[x,y][1]>30 or pixdata[x,y][2]>30 or pixdata[x,y][3]==0:
pixdata[x, y] = (255, 255, 255, 255)
image.show()
运行一下,对比看看图像处理前后的样子,简直完美的达到了我们的预期!

然后再测试一下识别效果,这次就没什么意外啦,完美识别!
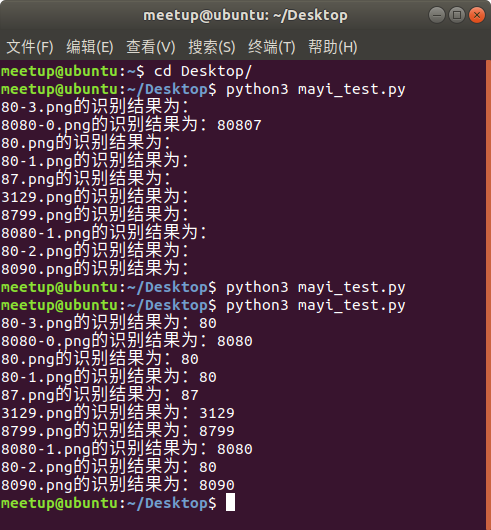
# 根据特征优化后
images = os.listdir("./mayidaili/")
for image_name in images:
image = Image.open("./mayidaili/%s" % image_name)
pixdata = image.load()
for y in range(image.size[1]):
for x in range(image.size[0]):
if pixdata[x,y][0]>30 or pixdata[x,y][1]>30 or pixdata[x,y][2]>30 or pixdata[x,y][3]==0:
pixdata[x, y] = (255, 255, 255, 255)
result = pytesseract.image_to_string(image)
print("%s的识别结果为:%s" %(image_name, result))
搞定蚂蚁代理的图片反爬虫
图像识别测试完毕后,基本就可以写代码将此免费代理IP来源配置至我们的代理池中了。可是意外的发现在进行端口号图片保存的时候,尽然保存不了?最终发现在请求图片时,有一条可疑的Cookie信息:proxy_token。一般的网站都只会对图片访问频率做限制,还很少见有这样验证图片访问Cookie的,可见站长的反爬做的很用心啊,哈哈哈~
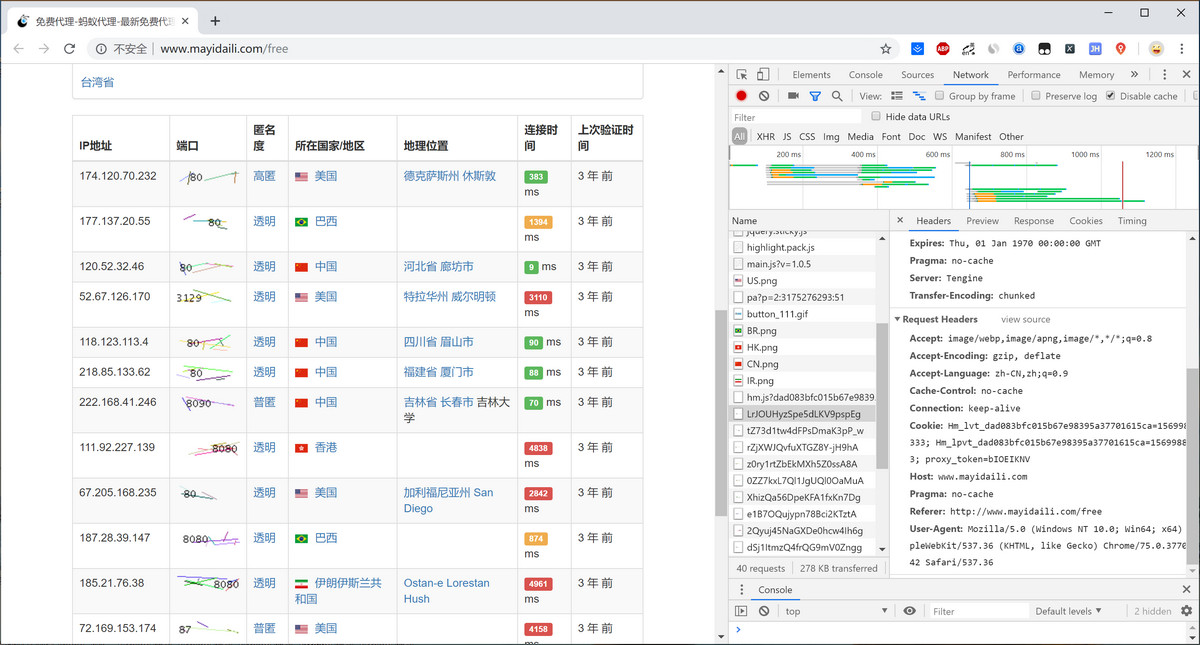
这条Cookie从哪里来的呢?一顿找,发现是在页面生成的时候,一段JS代码生成的Cookie值。(就在页面的最下方,很容易找到)我们只需要请求此页面后,将此Cookie值解析出来,然后请求图片的时候带上就可以了。
<script language="javascript">
$(function(){
document.cookie="proxy_token=wbazccxe;path=/";
$("img.js-proxy-img").each(function(index,item){
$(this).attr("src",$(this).attr("data-uri")).removeAttr("data-uri");;
});
});
</script>
相关资源推荐:
- Python爬虫快速入门,爬虫进阶学习路线,以及爬虫知识体系总结
- 利用Python爬取epubw整站27502本高质量电子书,并自动保存至百度网盘(内附分享)
- 利用Python实现百度网盘自动化:转存分享资源,获取文件列表,重命名,删除文件,创建分享链接等等
- 抖音短视频无水印解析下载,换个角度让爬虫更简单
- 巧办法解析tiktok无水印视频下载地址,轻松搞定tiktok无水视频下载!
- Python利用youtube-dl库快速搭建视频解析下载网站,支持下载1000+网站的视频
- 利用Python打造免费、高可用、高匿名的IP代理池
- 利用Python进行简单的OCR图像识别,解决爬虫中的验证码、图像文字识别等问题